Adding Trigram to Speculative Decoding
Speculative decoding uses a cheap draft model to propose candidate tokens, then verifies them against the target model in a single forward pass. The draft model does not need to be good. It needs to be cheap, plausible, and able to return the probability of whatever it sampled.
The previous speculative decoding post used a bigram draft, just like the one from Andrej Karpathy’s original nanoGPT implementation - one token of context, one lookup table:
P(next_token | current_token)
This post upgrades the draft to a trigram:
P(next_token | previous_token, current_token)
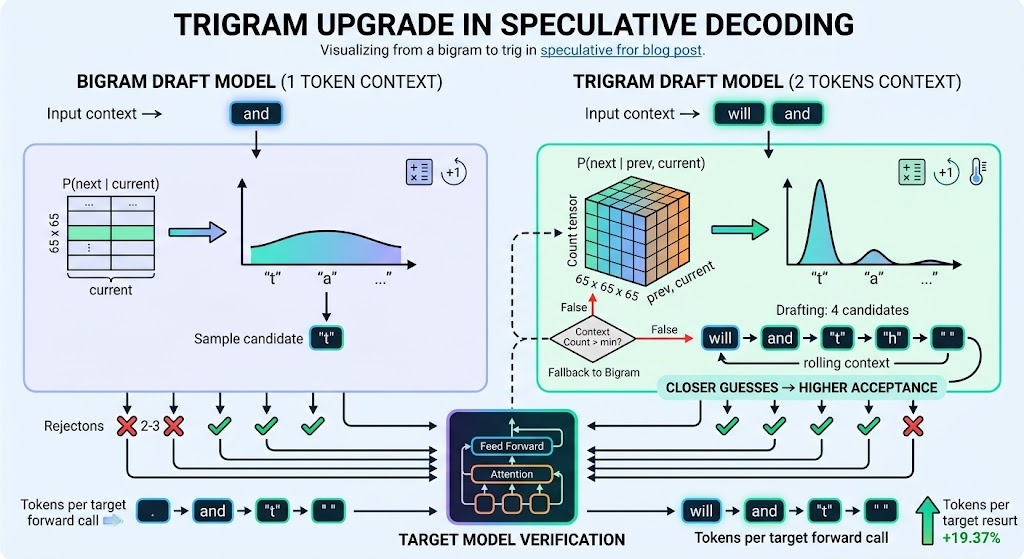
One additional token of context. The hypothesis is straightforward: if the draft sees more context, its guesses move closer to the target distribution. Closer guesses produce higher acceptance. Higher acceptance produces more tokens per target forward call.
Why trigram over bigram
A bigram table stores a distribution for each single token. When the current token is "t", the bigram must average over every possible preceding context:
" t" → likely "h" or "o"
"ht" → probably rare
"st" → maybe " " or another letter
A trigram distinguishes these cases. It conditions on both the previous token and the current token, producing a sharper prediction for each specific two-token context.
This is still a weak language model. It knows nothing about syntax, meaning, attention, or long-range dependencies. But for speculative decoding, the draft model’s job is narrow: guess plausibly, guess cheaply, and report the probability of each guess accurately.
Building the table
The trigram table is a 3D count tensor:
counts[a, b, c] = number of times token c followed context (a, b)
For a character-level Shakespeare vocabulary of ~65 tokens, this table has 65 × 65 × 65 = 274,625 entries. Compared to the bigram table, this sounds large. In absolute terms, it is a few hundred thousand floats - no matrix multiplications, no attention, no layers. Just indexing.
class TrigramDraftModel:
def __init__(self, token_ids, vocab_size, device, fallback_bigram=None, min_context_count=2):
counts = torch.zeros(vocab_size, vocab_size, vocab_size, dtype=torch.float32)
ids = torch.as_tensor(token_ids, dtype=torch.long).flatten().cpu()
for a, b, c in zip(ids[:-2].tolist(), ids[1:-1].tolist(), ids[2:].tolist()):
if 0 <= a < vocab_size and 0 <= b < vocab_size and 0 <= c < vocab_size:
counts[a, b, c] += 1.0
self.context_counts = counts.sum(dim=-1)
counts += 1.0
self.probs = counts / counts.sum(dim=-1, keepdim=True)
self.probs = self.probs.to(device)
self.context_counts = self.context_counts.to(device)
self.fallback_bigram = fallback_bigram
self.min_context_count = min_context_count
The construction has three stages.
Counting. A sliding window scans all consecutive triples (a, b, c) in the training data:
tokens: [x0, x1, x2, x3, x4, ...]
window: (x0, x1, x2)
window: (x1, x2, x3)
window: (x2, x3, x4)
Each triple increments counts[a, b, c].
Evidence tracking. Before smoothing, the total count per context is saved:
context_counts[a, b] = number of times context (a, b) appeared
This matters because trigram tables are sparse. Some contexts appear thousands of times. Some appear once. Some never appear. The model should not trust all rows equally.
Smoothing and normalization. Laplace smoothing (+1) ensures no probability is zero, then each row is normalized:
self.probs[a, b, c] = P(c | a, b)
Zero probabilities would break speculative decoding’s accept/reject math, which computes the ratio target_prob[token] / draft_prob[token]. Smoothing keeps every token legal.
Retrieving probabilities
The central method returns the distribution the draft model will sample from:
def get_probs(self, prev_token_id, token_id, temperature=1.0):
if prev_token_id is None:
probs = self.fallback_bigram.get_probs(token_id)
else:
prev_token_id = int(prev_token_id)
token_id = int(token_id)
if (
self.fallback_bigram is not None
and self.context_counts[prev_token_id, token_id] < self.min_context_count
):
probs = self.fallback_bigram.get_probs(token_id)
else:
probs = self.probs[prev_token_id, token_id]
if temperature == 1.0:
return probs
scaled = probs.clamp_min(1e-12).pow(1.0 / temperature)
return scaled / scaled.sum()
The normal path is a single index operation:
self.probs[prev, current] → (vocab_size,)
That one row is the full next-token distribution.
Two fallback cases handle edge conditions:
No previous token. At the start of generation, only one token of context exists. The model falls back to the bigram: P(next | current).
Rare context. Laplace smoothing makes every row valid, but not every row informative. If a context appeared fewer than min_context_count times in training, its smoothed trigram row is mostly a weak prior. A bigram row with thousands of observations is more useful. The policy:
If the trigram context has enough evidence → use P(next | prev, current)
Otherwise → fall back to P(next | current)
This keeps the trigram sharp when it has evidence and conservative when it does not.
Temperature
Temperature is applied after selecting the trigram or fallback row:
scaled = probs.clamp_min(1e-12).pow(1.0 / temperature)
return scaled / scaled.sum()
temperature < 1.0 → sharper, more greedy
temperature = 1.0 → unchanged
temperature > 1.0 → flatter, more random
The critical invariant: draft_probs[i] must match the distribution that produced candidates[i]. If a candidate is sampled from the temperature-scaled distribution but the unscaled distribution is returned, the accept/reject math is wrong and the algorithm no longer preserves the target model’s output distribution.
The clamp_min(1e-12) is a numerical guard. Laplace smoothing should already prevent zero probabilities, but device moves and dtype changes can introduce edge cases.
Sampling
Sampling is a wrapper around get_probs:
def sample(self, prev_token_id, token_id, *, temperature=1.0, generator=None):
probs = self.get_probs(prev_token_id, token_id, temperature=temperature)
next_token = torch.multinomial(probs, num_samples=1, generator=generator).item()
return next_token, probs
Both the sampled token and the distribution that produced it are returned. The second return value is not optional - the speculative accept/reject step requires the draft probability of each sampled token.
Drafting candidates
The draft phase changes slightly because the trigram requires two tokens of rolling context:
def draft_tokens(draft_model, prev_token, current_token, K, temperature=1.0):
candidates = []
draft_probs = []
a = prev_token
b = current_token
for _ in range(K):
next_token, probs = draft_model.sample(a, b, temperature=temperature)
candidates.append(next_token)
draft_probs.append(probs)
a, b = b, next_token
return candidates, draft_probs
The context rolls forward with each draft token:
(prev_token, current_token) → candidate_0
(current_token, candidate_0) → candidate_1
(candidate_0, candidate_1) → candidate_2
This rolling context is internal to the draft model. The target model does not need to know that the draft used a trigram.
The speculative loop
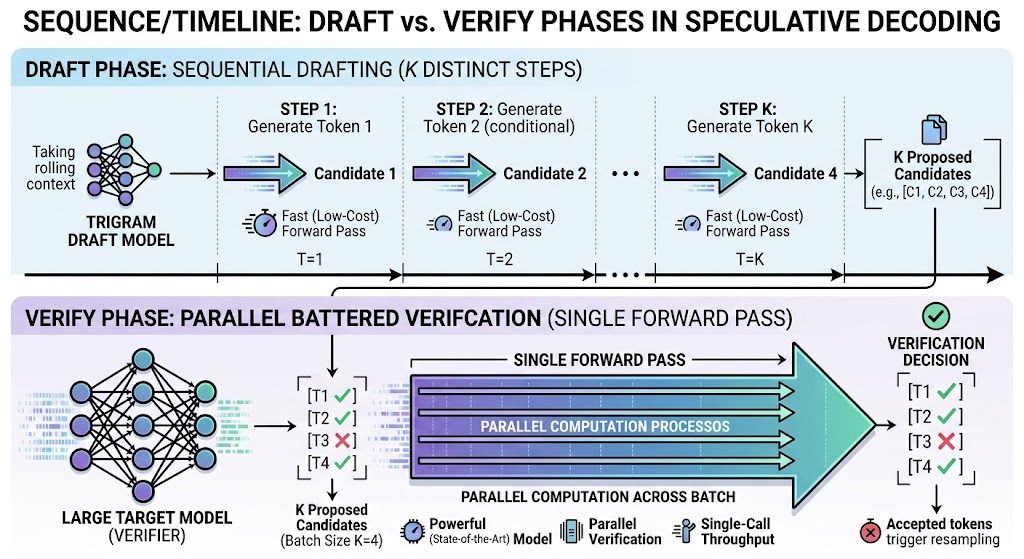
Target verification is unchanged from the bigram version. Only two pieces of draft state are new.
Initialization:
prev_token = prompt_tokens[-1]
Update after accepted tokens:
for token in accepted:
prev_token, current_token = current_token, token
The draft model always needs the last two emitted tokens. After every accepted token, the pair rolls forward.
The full loop:
@torch.no_grad()
def speculative_generate(target_model, draft_model, prompt_tokens, max_new_tokens, K=4):
target_model.eval()
generated = []
input_ids = torch.tensor([prompt_tokens], dtype=torch.long, device=device)
positions = torch.arange(len(prompt_tokens), device=device).unsqueeze(0)
logits, _, past_kvs = target_model(input_ids, pos=positions)
probs = F.softmax(logits[0, -1, :], dim=-1)
current_token = torch.multinomial(probs, num_samples=1).item()
generated.append(current_token)
prev_token = prompt_tokens[-1]
while len(generated) < max_new_tokens:
cache_len = past_kvs[0][0][0].shape[1]
k = min(K, max_new_tokens - len(generated))
candidates, draft_probs = draft_tokens(
draft_model,
prev_token,
current_token,
k,
)
target_probs, new_kvs = verify_candidates(
target_model,
current_token,
candidates,
past_kvs,
)
accepted = accept_reject(candidates, draft_probs, target_probs)
past_kvs = trim_kv_cache(new_kvs, len(accepted), cache_len)
generated.extend(accepted)
for token in accepted:
prev_token, current_token = current_token, token
return generated[:max_new_tokens]
One important detail: if accept_reject emits a resampled token after rejection, that token must update (prev_token, current_token). The next draft context must reflect the actual output sequence, not the rejected candidate chain.
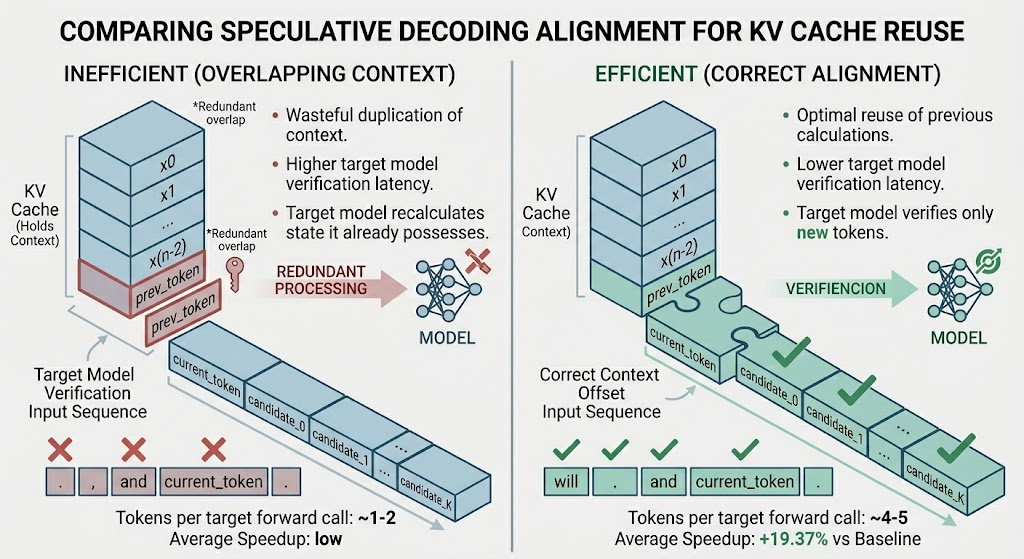
A common verification mistake
Because the draft model uses prev_token, it is tempting to include prev_token in the verification input. This is incorrect. The target model already has everything before current_token in its KV cache.
wrong: [prev_token, current_token, candidate_0, candidate_1, ...]
right: [current_token, candidate_0, candidate_1, ...]
The rule: verification input starts exactly where the KV cache ends.
Implementation constraints
Several constraints apply when the draft model changes from bigram to trigram:
- Distribution-sample consistency.
draft_probs[i]must be the exact distribution that producedcandidates[i], including temperature. Recomputing with a different rolling context breaks rejection sampling. - Verification boundary.
prev_tokenis already in the KV cache. Verification starts from[current_token] + candidates. - Sparse context handling. A smoothed trigram row from a context seen once may be worse than a bigram row seen thousands of times. This is why
min_context_countand bigram fallback exist. - Dense storage limits. A
(65, 65, 65)tensor works for character-level nanoGPT. For a 50k-token LLM vocabulary, dense trigram storage is infeasible. Production n-gram proposers use sparse maps, suffix arrays, or retrieval-style methods. - State update discipline. The draft context is always the last two real output tokens. If rejection produces a resampled token, that token becomes part of the real sequence and must update the context pair.
Summary
The trigram upgrade is a minimal change to the speculative decoding pipeline. The target model is unchanged. Verification is unchanged. The KV cache rule is unchanged.
Only the draft model gains one additional token of context:
bigram: P(next | current)
trigram: P(next | previous, current)
That extra context produces sharper draft predictions, which should increase acceptance and improve throughput. Bigram fallback prevents the model from over-trusting rare trigram contexts.
The broader point is not that a trigram is a good language model. It is not. The point is that speculative decoding rewards any cheap model that is just good enough to guess ahead - and a trigram table is one step closer to “good enough” than a bigram.
You can find the entire code here: https://github.com/czhou578/multimodal-inference-visualizer/blob/main/nanogpt-trigram-spec-decode.py
CZ