NanoGPT - Radix Tree Prefix Caching
In the previous post, we built a hash-chained prefix cache - a flat map of (parent_hash, token_ids) → KV block that lets requests skip redundant prefill work when they share a common prompt prefix. It works, but it has a pretty fundamental limitation: it doesn’t know what a tree is.
Consider a multi-turn conversation where a user asks two follow-up questions branching off the same context. The flat cache stores each block independently with MD5 hashes. It has no idea that blocks 0, 1, and 2 form a shared trunk that both branches depend on. So when memory gets tight, the LRU eviction policy might evict block 1 - silently orphaning everything downstream and making the cache useless.
This post replaces the flat cache with a radix tree (compressed trie), which is the same data structure that SGLang uses in production for RadixAttention. The tree structure makes prefix sharing explicit: shared trunks are interior nodes, branches are children, and eviction only happens at leaves. The result is dramatically better behavior under memory pressure.
Let’s look at the numbers first, then I’ll walk through how the tree works.
Results

Here’s the summary across six benchmark scenarios:
| Scenario | Requests | Prompt Tok | Flat Cached Tok | Radix Cached Tok | Flat Hit Rate | Radix Hit Rate | Flat Throughput | Radix Throughput | Flat Evictions | Radix Evictions |
|---|---|---|---|---|---|---|---|---|---|---|
shared_prefix_basic |
8 | 192 | 112 | 112 | 77.8% | 87.5% | 0.94x | 1.02x | 0 | 0 |
high_reuse_many_requests |
24 | 672 | 552 | 552 | 85.2% | 95.8% | 0.77x | 0.82x | 0 | 0 |
branching_conversation |
8 | 256 | 168 | 168 | 84.0% | 87.5% | 0.87x | 1.10x | 0 | 0 |
multi_prefix_groups |
24 | 576 | 320 | 320 | 76.9% | 83.3% | 0.70x | 0.91x | 0 | 0 |
low_reuse_control |
8 | 192 | 0 | 0 | 0.0% | 0.0% | 0.87x | 0.99x | 0 | 0 |
eviction_pressure |
24 | 576 | 0 | 288 | 0.0% | 79.2% | 0.76x | 0.91x | 136 | 0 |
Two things jump out immediately. First, the radix tree beats the flat cache in every single scenario - higher hit rates, higher throughput, fewer evictions. Second, look at the eviction pressure row: the flat cache achieves a 0% hit rate with 136 evictions (it thrashes constantly and gets nothing useful), while the radix tree gets 79.2% with zero evictions. That’s the structural advantage showing up clearly.
I should note: both caching strategies are actually slower than no caching in most scenarios. That’s expected for our tiny model - the caching overhead (lookups, KV slicing, tree management) dominates when the actual matmuls take microseconds. The point is to demonstrate the mechanism, not to show production speedups.
Why the flat cache breaks down
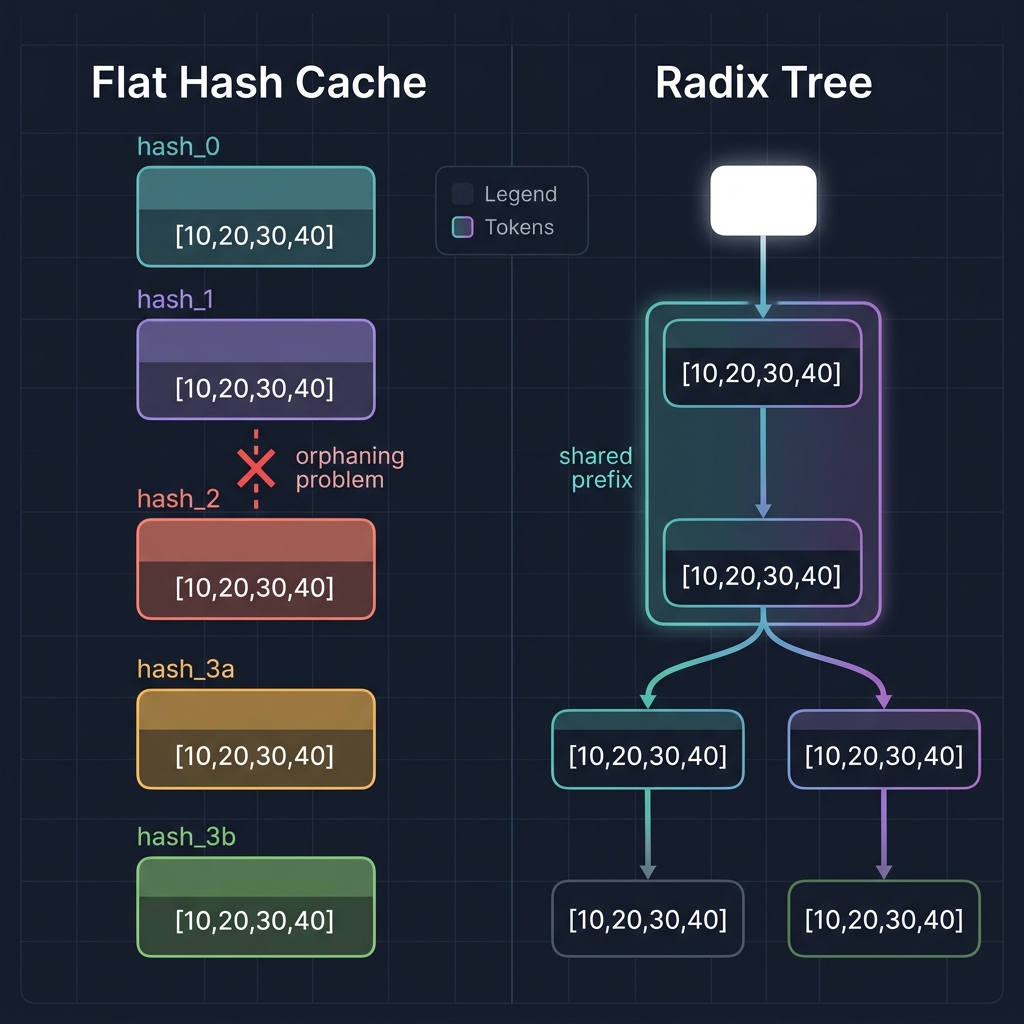
The flat hash map has three structural problems that become obvious once you think about trees:
No branching visibility. The cache stores blocks independently. Given a block hash, you can’t ask “what sequences extend this prefix?” Each block is an island.
Flat cache entries (no relationships):
hash_0 → [10, 20, 30, 40] (system prompt)
hash_1 → [50, 60, 70, 80] (user message)
hash_2 → [90, 11, 12, 13] (reply)
hash_3a → [14, 15, 16, 17] (follow-up A)
hash_3b → [18, 19, 21, 22] (follow-up B)
The flat map doesn’t know that hash_0 through hash_2 form a shared trunk that both hash_3a and hash_3b depend on. They’re just five unrelated entries.
Blind eviction. LRU on a flat map is dangerous. If the eviction policy removes hash_1, then hash_2, hash_3a, and hash_3b all become orphans - their chained hashes depend on hash_1 existing, so lookup walks will fail. The cache evicts a critical interior block while keeping useless leaf blocks. This is exactly what we see in the eviction pressure benchmark: 136 evictions, 0% hit rate.
Redundant traversal. Every call to find_cached_prefix() re-walks from block 0, re-hashing and re-looking-up every block in the chain. With a tree, shared prefixes are implicit edges - you walk once from root to the match point.
The radix tree
The fix is to make the prefix structure explicit. A radix tree (compressed trie) stores token sequences as paths from root to leaf. Shared prefixes are shared edges - stored once, referenced by all requests that pass through them.
A concrete example: multi-turn conversation
To see why this matters, let’s walk through a multi-turn conversation and watch the tree evolve step by step.
Turn 1 - initial prompt. A user sends: "You are a helpful assistant. What is a radix tree?" The tokenized prompt is [101, 202, 303, 404, 505, 606, 707, 808]. After prefill, the tree has one path:
ROOT
└─ [101, 202, 303, 404, 505, 606, 707, 808] ← KV for positions 0–7
Turn 2 - first follow-up. The user asks: "Give me a code example." The full prompt is the original 8 tokens plus the follow-up tokens [909, 110, 211, 312]. The tree matches the first 8 tokens from the cache (skipping all of that prefill work), then inserts the new suffix:
ROOT
└─ [101, 202, 303, 404, 505, 606, 707, 808] ← shared trunk (cached)
└─ [909, 110, 211, 312] ← follow-up A
Turn 3 - second follow-up (branching). The user goes back and asks a different question instead: "How does it compare to a trie?" This shares the same 8-token trunk but has different follow-up tokens [413, 514, 615, 716]. The tree matches the trunk again, then creates a second branch:
ROOT
└─ [101, 202, 303, 404, 505, 606, 707, 808] ← shared trunk (cached, 2 dependents)
├─ [909, 110, 211, 312] ← follow-up A
└─ [413, 514, 615, 716] ← follow-up B
The trunk’s KV data is stored once and reused by both branches. If memory gets tight, the eviction policy can remove either leaf without affecting the shared trunk - the interior node is structurally protected.
Now imagine a flat cache holding the same data. It has 12 independent hash entries with no knowledge that entries 0–7 form a shared prefix. Evicting any one of them orphans everything downstream. The radix tree makes this impossible by construction.
Here’s the node structure:
class RadixNode:
children: Dict[int, RadixNode] # first token of child → child node
parent: Optional[RadixNode] # back-pointer for path walking
token_ids: Tuple[int, ...] # variable-length token sequence (compressed edge)
kv_data: Optional[Dict] # KV cache tensors for this edge's tokens
lock_ref: int # reference count - active requests pin this node
last_access_time: int # for LRU eviction among leaves
The children dict is keyed by the first token of the child’s token_ids. This is a nice design choice: given the next token in a query, node.children.get(next_token) finds the right child edge in O(1). If the child’s edge is (10, 20, 30, 40), you match on token 10 to find it, then compare the rest of the edge against the query.
How it works
Matching a prefix
The central operation walks the tree from root, consuming query tokens as it matches edges:
- At each node, look up
children[next_token] - Compare the query against the child’s full edge token sequence
- If the edge fully matches, move to the child and continue
- If the match ends mid-edge, stop - we’ve found the exact divergence point
- If no child starts with the next token, stop
When we find a match, we collect KV data from every node along the path. The request’s KV cache is built by concatenating these tensors in order - the tree walk naturally produces the full cached prefix.
Splitting nodes - the tricky part
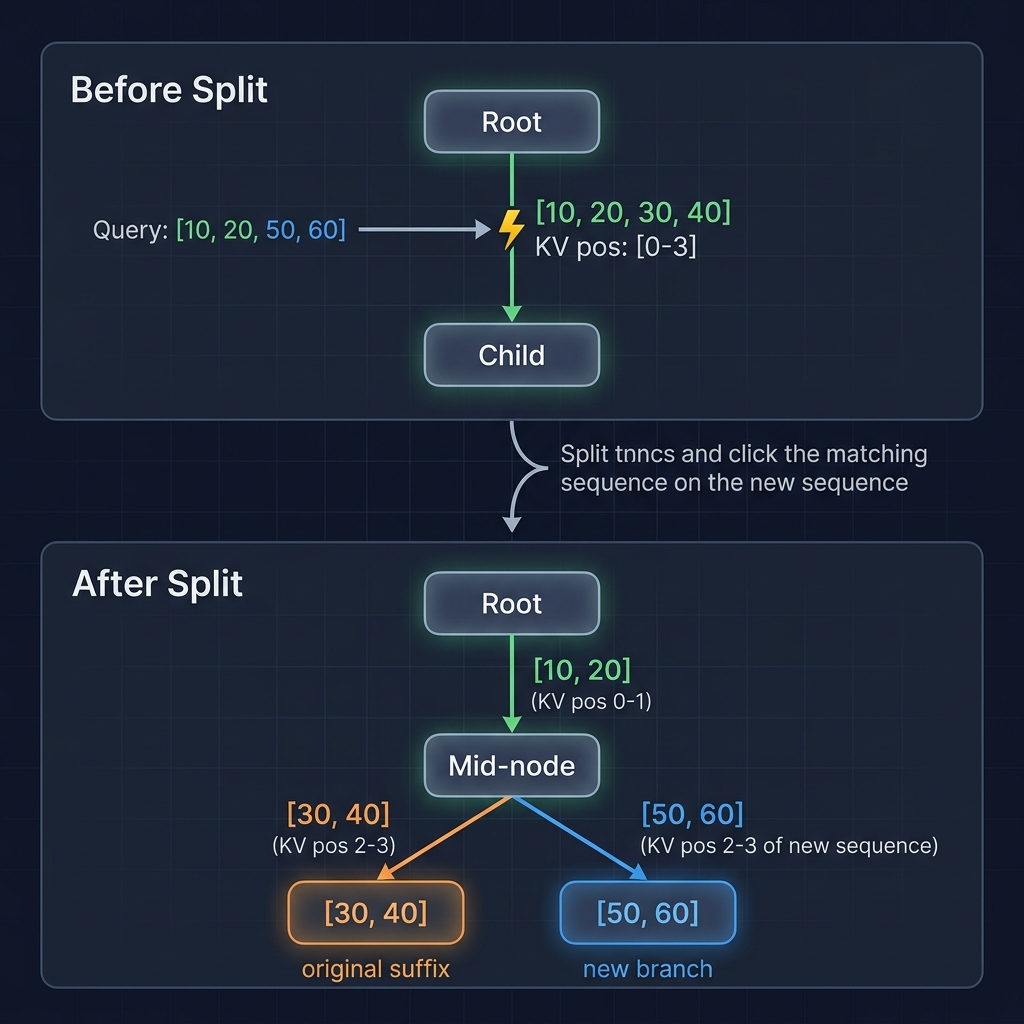
This is where things get interesting. When a new sequence partially matches an existing edge, the edge has to be split:
Before: root → [10, 20, 30, 40] (node A, KV for positions 0-3)
Query: [10, 20, 50, 60] - match stops at position 2
After: root → [10, 20] (new mid-node B, KV for positions 0-1)
→ [30, 40] (old node A, KV for positions 2-3)
→ [50, 60] (new node C, KV for positions 2-3 of new sequence)
The split creates a new mid-node with the matched prefix, shortens the old child to the unmatched suffix, and divides the KV tensors between them. Each key and value tensor is stored in kv_data with shape (1, num_tokens, head_dim). Since the sequence length (number of tokens) is the second dimension (dim=1), we split them by slicing along that dimension using .clone() (to avoid shared tensor storage corruption).
The mid-node gets the first half k[:, :split_len, :], and the old child gets the second half k[:, split_len:, :].
There’s also a subtle invariant: if the old child was pinned (lock_ref > 0), the new mid-node must inherit that lock count. Otherwise, an active request’s prefix path could get evicted mid-generation.
Here is the implementation of _split_node and the subsequent insert routine:
def _split_node(self, child: RadixNode, split_len: int) -> RadixNode:
"""Split child's edge at position split_len. Returns the new mid-node."""
new_mid = RadixNode()
new_mid.token_ids = child.token_ids[:split_len]
new_mid.parent = child.parent
new_mid.last_access_time = child.last_access_time
new_mid.lock_ref = child.lock_ref # Inherit lock reference count
if child.kv_data is not None:
new_mid.kv_data = {}
new_child_kv = {}
# Divide the KV tensors along dim=1 (the sequence/token dimension)
for (layer, head), (k, v) in child.kv_data.items():
new_mid.kv_data[(layer, head)] = (
k[:, :split_len, :].clone(),
v[:, :split_len, :].clone()
)
new_child_kv[(layer, head)] = (
k[:, split_len:, :].clone(),
v[:, split_len:, :].clone()
)
child.kv_data = new_child_kv
suffix_tokens = child.token_ids[split_len:]
child.token_ids = suffix_tokens
child.parent = new_mid
new_mid.children[suffix_tokens[0]] = child
new_mid.parent.children[new_mid.token_ids[0]] = new_mid
return new_mid
def insert(self, token_ids: List[int], kv_data_full: Dict, block_size: int):
"""Insert token_ids and their KV data into the tree."""
node, matched = self.match_prefix(token_ids)
if matched == len(token_ids):
return
remaining = token_ids[matched:]
new_node = RadixNode()
new_node.token_ids = tuple(remaining)
new_node.parent = node
new_node.last_access_time = self.step
new_node.kv_data = {}
# Slice the newly generated KV tensors starting from the matched prefix end
for (layer, head), (k, v) in kv_data_full.items():
new_node.kv_data[(layer, head)] = (
k[:, matched:matched + len(remaining)].clone(),
v[:, matched:matched + len(remaining)].clone()
)
node.children[remaining[0]] = new_node
I got the KV slicing assignments swapped the first time. Getting this backwards produces silent data corruption: the model gets KV entries from the wrong positions and generates garbage, but nothing crashes. Using .clone() on the sliced tensors is critical to avoid shared storage issues when the tensors are mutated downstream.
Leaf-first eviction
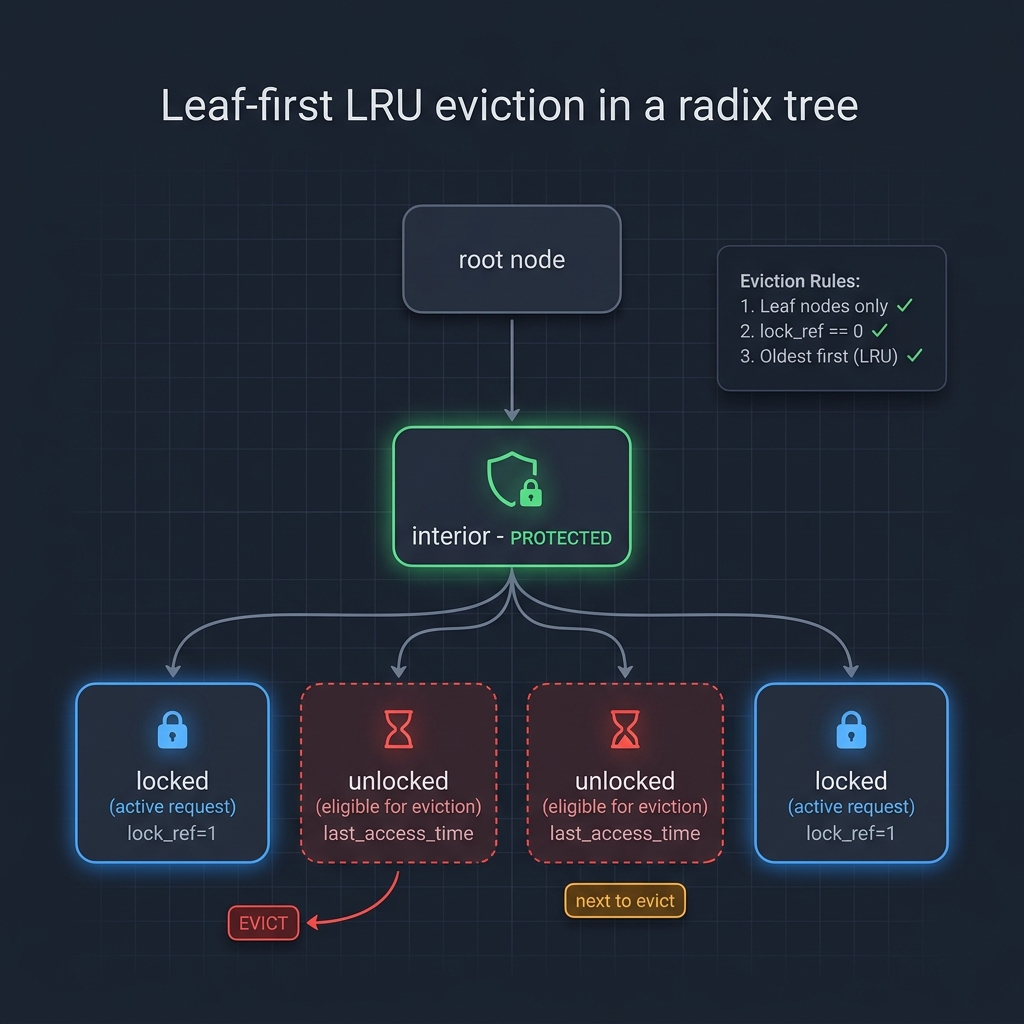
This is the radix tree’s killer feature. The eviction rule is:
- Only evict leaf nodes (no children)
- Only evict unlocked nodes (
lock_ref == 0) - Among eligible leaves, pick the oldest (LRU by
last_access_time)
Here’s the implementation:
def evict_lru(self) -> bool:
"""Evict the least-recently-used unlocked leaf node."""
leaves = []
self._find_leaves(self.root, leaves)
# Filter to eligible leaves (not locked, and not the root)
candidates = [n for n in leaves if n.lock_ref == 0 and n != self.root]
if not candidates:
return False # nothing to evict
# Find the oldest leaf node
victim = min(candidates, key=lambda n: n.last_access_time)
# Prune it from the parent
parent = victim.parent
del parent.children[victim.token_ids[0]]
# Free memory
victim.kv_data = None
victim.parent = None
return True
The structural guarantee: an interior node (shared prefix) cannot be evicted while it still has children depending on it. The tree topology prevents orphaned blocks by construction. This is why the eviction pressure benchmark shows 0 evictions for the radix tree - interior nodes are protected.
Compare this to the flat cache, which has no concept of “interior” vs “leaf.” It evicts any block regardless of what depends on it. That’s why it thrashes to a 0% hit rate under memory pressure.
Reference counting
When a request loads KV data from the tree, every node along the matched path gets lock_ref += 1. This prevents eviction of nodes that an active request depends on. When the request completes (after prefill or after generation finishes), the path gets unpinned with lock_ref -= 1.
def load_from_radix_tree(request, tree, prompt_tokens, block_size):
"""Load cached KV from the radix tree onto a request."""
node, matched = tree.match_prefix(prompt_tokens)
if matched == 0:
return 0
# Walk up parent pointers from matched node to assemble the full path
prefix_path = []
curr = node
while curr != tree.root:
prefix_path.append(curr)
curr = curr.parent
prefix_path.reverse()
# Concatenate the KV tensors along dim=1 (the sequence/token dimension)
# The shape of each KV tensor is (1, num_tokens, head_dim)
for (layer, head) in prefix_path[0].kv_data.keys():
new_k, new_v = [], []
for pnode in prefix_path:
pk, pv = pnode.kv_data[(layer, head)]
new_k.append(pk.clone())
new_v.append(pv.clone())
request.kv_cache[(layer, head)] = (
torch.cat(new_k, dim=1),
torch.cat(new_v, dim=1),
)
# Pin every node along the matched path
for pnode in prefix_path:
pnode.lock_ref += 1
# Snap to block boundary for prefill_cursor
num_cached = (matched // block_size) * block_size
request.prefill_cursor = num_cached
request._radix_path = prefix_path # Save path for later unlocking
return num_cached
def unlock_radix_path(self, request):
"""Release the tree locks acquired during load_from_radix_tree."""
path = getattr(request, '_radix_path', None)
if path is None:
return
for node in path:
node.lock_ref -= 1
request._radix_path = None
This is the same mechanism SGLang calls inc_lock_ref / dec_lock_ref in production. Without it, the eviction logic could free nodes that an active request’s KV cache is currently pointing to.
Integration with the scheduler
The scheduler changes are minimal. The BlockCache gets replaced with a RadixTree, but the interface to the model is identical:
| Operation | Flat Cache | Radix Tree |
|---|---|---|
| Check prefix | find_cached_prefix() - hash-chain walk |
match_prefix() - tree traversal |
| Load cached KV | Hash lookup per block | Walk path, collect KV |
| Commit new KV | Hash + insert per block | Tree insert at divergence point |
| Release locks | N/A | unlock_radix_path() |
| Eviction | Flat LRU (any block) | Leaf-first LRU (structural) |
The model, attention heads, assemble_batch_cache, and disassemble_batch_cache are completely unchanged - the model receives past_kvs the same way regardless of where they came from.
# In the decode loop - insertion happens when prefill completes
if prefill_req.is_fully_prefilled:
insert_into_radix_tree(prefill_req, scheduler.radix_tree, scheduler.block_size)
prefill_req.generated_tokens.append(idx_next.item())
prefill_req._last_token = idx_next
scheduler.radix_tree.unlock_radix_path(prefill_req)
scheduler.promote(prefill_req)
What the benchmarks show
The eviction pressure scenario
This is the most revealing test. The setup: max_cache_blocks=8 (tiny cache), 6 prefix groups, 16-token shared prefixes.
Flat cache: 0% hit rate, 136 evictions, 0 cached tokens. The LRU evicts interior blocks that later requests need, orphaning everything downstream. The cache churns constantly with zero benefit.
Radix tree: 79.2% hit rate, 0 evictions, 288 cached tokens (50% prefill reduction). Interior nodes are protected by the leaf-first rule. Branches can be evicted without damaging the shared trunk.
The branching conversation scenario
This workload simulates a multi-turn chat: one shared trunk (24 tokens) branches into 8 different follow-up conversations (8 tokens each). This is exactly the tree shape a radix tree is designed for:
RadixTree:
[] (ROOT)
[trunk tokens...] (shared by all 8 branches)
[branch_0 suffix]
[branch_1 suffix]
...
[branch_7 suffix]
The radix tree achieves 1.10x throughput over no caching - the only caching strategy that actually speeds things up. The flat cache is at 0.87x (slower than no caching).
Low reuse control
With unique prompts (no shared prefixes), neither strategy can help. But the overhead difference is stark:
- Flat cache: 0.87x (13% overhead) - still pays per-block hashing and insertion for all 48 blocks
- Radix tree: 0.99x (1% overhead) - inserts one node per prompt with no hashing
Memory efficiency
The radix tree uses fewer cache entries while achieving equal or better reuse:
| Scenario | Flat Entries | Radix Entries | Flat Overhead |
|---|---|---|---|
shared_prefix_basic |
20 | 9 | 2.2x more |
branching_conversation |
22 | 10 | 2.2x more |
low_reuse_control |
48 | 8 | 6.0x more |
Variable-length edges beat fixed 4-token blocks.
Verification
A few sanity checks that confirm the tree is working correctly:
Token accounting. In every shared-prefix scenario, cached_tok + prefill_tok == prompt_tok. No tokens are double-counted or lost:
| Scenario | prompt_tok | cached_tok | prefill_tok | Sum |
|---|---|---|---|---|
shared_prefix_basic |
192 | 112 | 80 | 192 ✓ |
branching_conversation |
256 | 168 | 88 | 256 ✓ |
Flat-radix parity. In every non-eviction scenario, flat and radix achieve identical cached_tok counts. The data structure is different, but the semantic result is the same.
Zero false positives. Both strategies correctly report 0% hit rate and 0 cached tokens when prompts have no shared prefixes.
Lock safety. No benchmark crashes due to eviction-of-pinned-nodes errors. The lock_ref mechanism correctly prevents eviction of active nodes.
Caveats
- The model is tiny (57K parameters). Production benefits scale with model size.
- Running on CPU, not GPU. GPU memory management would change the overhead profile.
- Prompts are short (16–32 tokens). The radix tree matters more with longer prefixes (256+ tokens) where compute savings dominate overhead.
- Single-run results; production benchmarks should report repeated statistics.
Takeaways
Tree structure provides safety that flat maps cannot. Under memory pressure, the radix tree’s leaf-first eviction automatically protects shared interior nodes. The flat cache has no concept of “interior” vs “leaf” - it evicts any block, potentially orphaning entire chains.
Branching workloads are the sweet spot. Multi-turn conversations, agent reasoning branches, and A/B prompt testing all create branching token sequences. The radix tree represents these naturally. The flat cache stores each branch as independent hash-chained blocks with no structural relationship.
Node splitting is the hardest implementation detail. Getting the KV data division, parent/child re-wiring, and lock_ref inheritance right requires careful attention. Incorrect splitting produces silent data corruption that’s hard to catch without equivalence tests.
This is the same approach used in production. The radix tree is the data structure behind SGLang’s RadixAttention. Multi-turn chat, agent workflows, RAG with shared document prefixes, batch inference with shared instruction templates - all benefit from making prefix sharing structurally explicit.
You can find the full source code here: https://github.com/czhou578/multimodal-inference-visualizer/blob/main/nanogpt-radix-tree-.py
CZ