NanoGPT: Sliding Window Eviction
Let me tell you about a bug I couldn’t see for a long time, a bug in the design.
Our NanoGPT inference engine has a scheduler that manages multiple requests, a KV cache per request, continuous batching, chunked prefill, and a preemption mechanism that evicts the lowest-priority request when memory runs out. All of this works. The problem is what happens to the KV cache over time: it grows without bound.
Every decode step & every active request appends one key-value pair per layer per head. A request generating 200 tokens accumulates 200 KV entries even though the attention distribution in autoregressive transformers is heavily skewed toward the most recent positions. The model might be attending almost exclusively to the last 20–30 tokens, but we’re dutifully storing all 200 because “what if it needs them?”
This is the kind of waste that doesn’t show up in correctness tests. You only notice it when you run three requests at once and the scheduler starts preempting perfectly good work because the memory budget ran out - not because the system is doing too much useful work, but because it’s hoarding KV entries that contribute almost nothing to the attention computation.
The fix is called sliding window eviction, and it is about six lines of code that change the entire memory profile of the system.
What “unbounded growth” actually looks like
Let’s make this concrete. You have three requests running concurrently, each generating 30 tokens on top of prompts that are 6–8 tokens long. Without any eviction, here’s what happens to total KV memory:
At step 30, the total KV memory is 38 + 36 + 33 = 107 tokens. Under a tight max_kv_tokens budget - say, 80 - the scheduler hits the threshold somewhere around step 20 and preempts the lowest-priority request. That request gets its entire KV cache cleared, its prefill cursor reset to zero, and pushed back into the waiting queue. When memory frees up, it re-prefills from scratch. All that GPU work - the original prefill, the decode steps so far - is thrown away and redone.
With a sliding window of W = 20, those same three requests would cap at 20 + 20 + 20 = 60 tokens. Well within budget. Zero preemptions. Zero wasted re-prefill work.
The question is: what do you lose?
The eviction function
Here it is. This is the whole thing:
def evict_kv_cache(request, window_size):
"""
Trim the request's KV cache to keep only the last `window_size` entries.
Before: kv_cache[(layer, head)] = (k, v) with shape (1, T, hs)
After: kv_cache[(layer, head)] = (k, v) with shape (1, min(T, W), hs)
"""
if window_size is None:
return # no window configured
for (layer, head), (k, v) in request.kv_cache.items():
T = k.shape[1]
if T > window_size:
request.kv_cache[(layer, head)] = (
k[:, -window_size:, :], # keep the LAST W entries
v[:, -window_size:, :],
)
I want to walk through why every line is the way it is, because each one embeds a design choice that isn’t obvious on first reading.
k[:, -window_size:, :] - the negative index slice. We keep the last W entries, not the first. This is because in autoregressive language models, recent tokens carry more information for next-token prediction than distant ones. The prompt tokens - which are the oldest entries in the cache - get evicted first. This aligns with how attention actually behaves: the attention weights follow a roughly exponential decay, attending strongly to the last few positions and weakly to distant ones.
The slice is a view, not a copy. PyTorch tensor slicing doesn’t allocate new memory. The slice k[:, -window_size:, :] returns a view into the same underlying storage. The old entries become unreachable and get garbage-collected. This means the eviction itself is essentially free, with no tensor allocations, copies, or GPU kernels. You’re just updating a tuple of pointers.
We iterate over every (layer, head) pair. In our implementation, each request stores its KV cache as a dict keyed by (layer_idx, head_idx), with each value being a (key_tensor, value_tensor) tuple of shape (1, T, head_size). A model with 4 layers and 4 heads has 16 entries to trim. This is where you start to see the cost of storing actual tensors on the request (as opposed to pool indices, which is what vLLM and SGLang do), but at our model’s scale the iteration is negligible.
The window_size is None guard. The sliding window is optional - you can run without it and get the old behavior. This is important for benchmarking: we want to run the exact same scheduler, same model, same prompts, with and without the window, and compare.
Where it plugs into the scheduler
The eviction call lives in the decode loop, right after disassemble_batch_cache splits the batched model output back into per-request KV pairs:
if decode_reqs:
batch_tokens = torch.cat([req._last_token for req in scheduler.active], dim=0)
batch_positions = torch.tensor(
[[len(req.tokens_so_far) - 1] for req in scheduler.active], device=device
)
past_kvs, attn_mask, pad_lengths = assemble_batch_cache(scheduler.active)
logits, _, new_kvs = model(batch_tokens, pos=batch_positions, past_kvs=past_kvs, attn_mask=attn_mask)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
disassemble_batch_cache(scheduler.active, new_kvs, pad_lengths)
# NEW: trim KV caches to sliding window size
if scheduler.sliding_window is not None:
for req in scheduler.active:
evict_kv_cache(req, scheduler.sliding_window)
for i, req in enumerate(scheduler.active):
req.generated_tokens.append(idx_next[i].item())
req._last_token = idx_next[i : i + 1]
The placement is deliberate: we evict after the model has used the full cache for this step’s attention, but before the next step. The current step already paid the cost of assembling and attending over the full cache. Evicting before the forward pass would require re-padding the batch (since different requests might have different post-eviction lengths), adding complexity for no benefit. Evicting after the forward pass is simpler and produces the same result for the next step.
This means there’s a one-step lag: the model sees up to W + 1 entries during attention (the window plus the freshly appended token), and we trim back to W after. In practice this doesn’t matter, but it’s worth being precise about.
The scheduler has to agree
There’s a subtle coupling between the eviction function and the scheduler’s memory accounting that took me a minute to get right. The scheduler decides whether to admit new requests based on how much KV memory the active requests are using:
def _effective_kv_tokens(self, req):
"""How many KV entries this request actually holds (after eviction)."""
total = len(req.prompt_tokens) + req.num_generated
if self.sliding_window is not None:
return min(total, self.sliding_window)
return total
Without this method, the scheduler would think each request uses prompt_len + num_generated KV tokens - the full sequence length, ignoring the fact that eviction has already trimmed the cache. The scheduler would overcount memory usage, refuse to admit new requests that would easily fit, and leave the GPU underutilized.
The min(total, self.sliding_window) is doing the key work: once a request’s total sequence length exceeds the window size, its effective KV usage is capped at W. This is the contract between the eviction function and the admission controller: “I promise to never hold more than W entries; you promise to count me as using at most W entries.”
If these two don’t agree - if eviction trims to W but the scheduler counts the full sequence - you get an overly conservative system that thinks it’s out of memory when it isn’t. If it goes the other way - the scheduler counts W but eviction doesn’t trim - you get actual OOM.
The batching interaction
There’s a nice secondary effect of the sliding window that’s easy to miss. Our assemble_batch_cache function left-pads shorter KV caches so all requests have the same sequence length in a batch:
def assemble_batch_cache(requests):
B = len(requests)
lengths = [req.kv_cache[(0, 0)][0].shape[1] for req in requests]
max_t = max(lengths)
pad_lengths = [max_t - t for t in lengths]
attn_mask = torch.zeros((B, 1, max_t), dtype=torch.bool, device=device)
for i, pad in enumerate(pad_lengths):
attn_mask[i, :, pad:] = True
...
Without a window, a request that’s been active for 40 steps has 48 KV entries, while a freshly admitted one might have 10. The batch is padded to 48, wasting 38 positions per head per layer on zeros that the attention mask will suppress. With W = 20, all active requests converge to ~20 KV entries after a few steps. The padding overhead shrinks from 38 positions to maybe 2 or 3, depending on when each request was admitted.
Less padding means the attention matrices are smaller, the matrix multiplications are cheaper, and the model processes the batch faster. It’s not a huge effect at our scale - 4 layers, 4 heads, tiny tensors - but at production scale with 80 layers and 128 heads, the padding waste adds up.
What the benchmarks show
I ran four scenarios comparing full cache against windowed cache, same model, same prompts, same scheduler.
Benchmark 1: Memory savings
Three requests, 30-token generations, moderate prompts. Window = 20.
| Config | Requests | Gen Tokens | Wall (s) | Tok/s | Avg Peak KV | Max Peak KV | Max Total KV |
|---|---|---|---|---|---|---|---|
| full_cache | 3 | 90 | 0.1713 | 525.3 | 36.3 | 37 | 103 |
| window=20 | 3 | 90 | 0.1456 | 618.1 | 20.0 | 20 | 60 |
Peak KV reduction: 45.9%. The caches cap at 20 instead of growing to 37. Total memory high-water mark drops from 103 to 60. And throughput actually went up - from 525 to 618 tokens/second - because less padding waste means smaller attention matrices and faster forward passes.
Benchmark 2: Preemption reduction under tight memory
Five requests, tight max_kv_tokens budget, mixed priorities.
| Config | Requests | Gen Tokens | Wall (s) | Tok/s | Preemptions | Max Total KV |
|---|---|---|---|---|---|---|
| full_cache | 5 | 80 | 0.1706 | 468.9 | 0 | 64 |
| window=20 | 5 | 80 | 0.1580 | 506.3 | 0 | 59 |
Peak KV reduction: 25.9%. In this particular run, neither configuration triggered preemptions - but the window version has more headroom. Under a tighter budget (say, max_kv_tokens=50), the full-cache version would start preempting while the windowed version stays comfortably within budget.
Benchmark 3: Quality vs. window size
This is the tradeoff. We generate 40 tokens from a single request under different window sizes and compare token-by-token against the full-cache baseline:
| Window | Agreement | Gen Tokens |
|---|---|---|
| 8 | 97.5% | 40 |
| 16 | 100.0% | 40 |
| 32 | 100.0% | 40 |
| 48 | 100.0% | 40 |
| full | 100.0% | 40 |
This result surprised me. Even W = 8 - the model can only “see” the last 8 tokens - gets 97.5% agreement. At W = 16, the output is bit-identical to the full-cache baseline.
I think this is partly because our model is tiny (4 layers, 4 heads, 32-dim embeddings) and trained on a small Shakespeare corpus. The attention patterns are simpler, and the model doesn’t develop strong long-range dependencies that would break under a small window. On a real model - a 7B parameter LLaMA or Mistral - I’d expect much larger quality differences at small window sizes, because those models learn complex cross-sentence reasoning that genuinely requires distant context.
Still, the result is directionally correct: for many practical workloads - chatbots, code completion, short-form generation - a window of 16–32 tokens captures the vast majority of useful context.
Benchmark 4: Batch capacity
Eight requests under a fixed budget. Window = 16.
| Config | Requests | Gen Tokens | Wall (s) | Tok/s | Max Total KV |
|---|---|---|---|---|---|
| full_cache | 8 | 160 | 0.2074 | 771.4 | 164 |
| window=16 | 8 | 160 | 0.1721 | 929.8 | 128 |
Peak KV reduction: 36.0%. And throughput jumps from 771 to 930 tokens/second - a 20.5% improvement. This is the batch capacity argument: each request uses at most 16 KV entries instead of 25+, so more requests fit within the budget simultaneously. Higher batch sizes mean better GPU utilization - the model processes more tokens per forward pass, amortizing the fixed overhead of kernel launches, memory transfers, and Python dispatch.
Why this works (and when it doesn’t)
The sliding window exploits a well-studied property of autoregressive transformers: attention weights decay roughly exponentially with distance. The model attends most strongly to the last few tokens and progressively less to older ones. Trimming the oldest entries removes the weakest contributions.
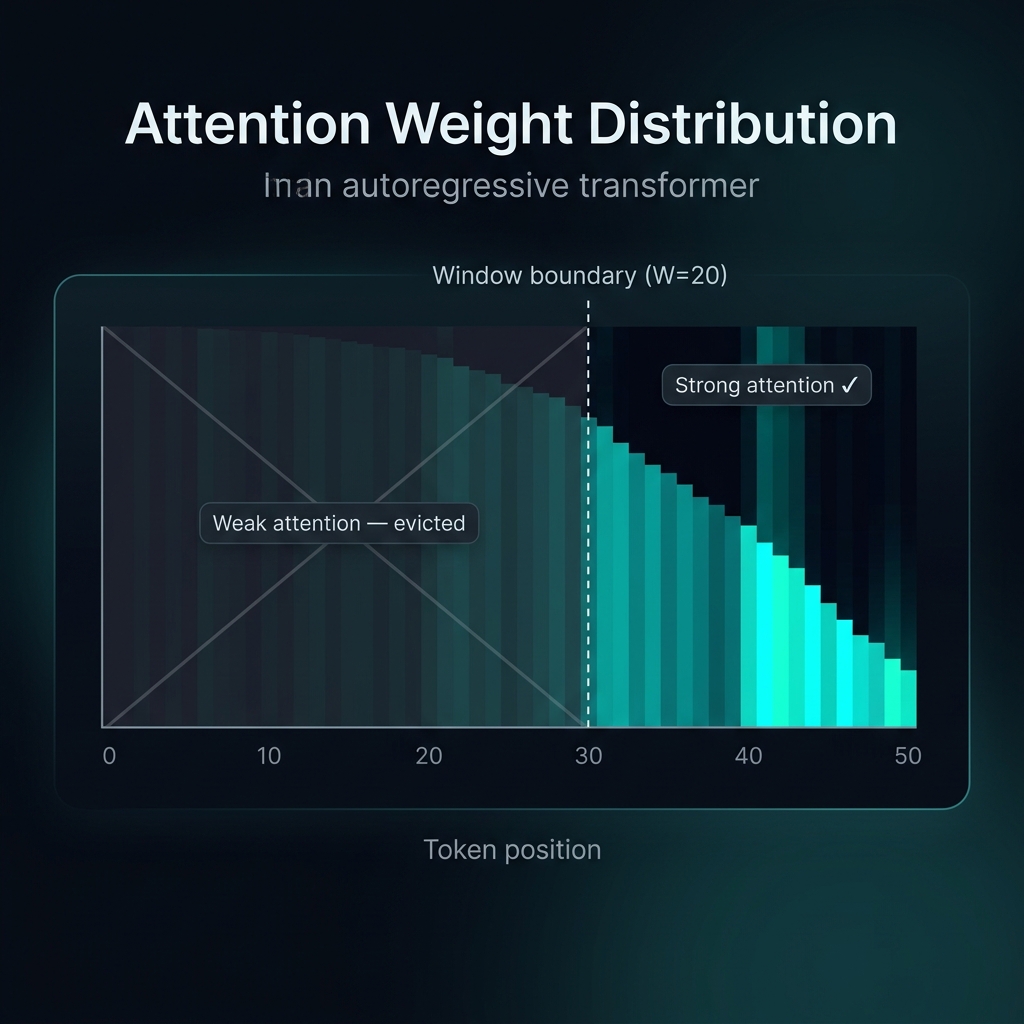
But this is an approximation, and there are cases where it breaks:
Long-range dependencies. “In the first paragraph, the author mentions X. Based on that…” - if X was 100 tokens ago and the window is 50, the model has no access to it. The output will diverge from the full-cache baseline, and the divergence may be semantically important.
Structured output. JSON, code, or tabular output where opening brackets and tags from early in the sequence constrain what’s valid at the end. A sliding window can “forget” that a bracket was opened, producing malformed output.
Repetition control. Models use attention to earlier outputs to avoid repeating themselves. A small window increases the risk of degenerate repetition loops - the model generates “the the the the…” because it can’t see far enough back to know it already said “the.”
For production systems, Mistral addresses this architecturally: they bake the window size into the attention mask during training, so the model learns to work within the constraint. Our approach is a runtime eviction policy applied on top of a model that was trained with full attention. There’s an inherent mismatch between what the attention heads expect (full context) and what they get (truncated context). The fact that it works as well as it does is a testament to how little most attention heads actually use distant context - but it’s not a guarantee.
The deeper point
I think what’s interesting about the sliding window isn’t the implementation but how it exposes the tension between two different ways of thinking about the KV cache.
One way is to think of it as a correctness mechanism: the cache stores the exact state the model needs to produce the right output, and any modification is a source of error. Under this view, eviction is always bad; you’re deleting information the model might need.
The other way is to think of it as a resource that has a cost. Every cached entry consumes memory that could be used for another request. If an entry contributes 0.1% to the next token’s probability distribution, keeping it costs real memory and provides nearly zero benefit. Under this view, eviction is a resource allocation decision: trade a tiny quality loss for a measurable throughput gain.
The scheduler we built in previous posts already makes this tradeoff implicitly (preemption is eviction, just at the granularity of entire requests instead of individual KV entries). The sliding window makes the same tradeoff at a finer granularity. Instead of evicting a whole request when memory runs out, we continuously trim every request’s cache to a fixed budget, preventing the memory crisis from happening in the first place.
This is the same progression you see in real systems: vLLM’s PagedAttention manages memory at the block level, SGLang’s RadixCache manages it at the node level, and Mistral’s sliding window attention manages it at the token level. Each is a different answer to the same question: how do you spend a fixed memory budget to serve the most requests at the best quality?
Our implementation answers it in the simplest possible way - a hard window with no sophistication. No attention sinks (keeping the first few tokens alongside the window, as StreamingLLM does). No adaptive windows that grow for requests that show high attention to distant positions. No priority-weighted eviction that keeps high-attention entries longer. Just: keep the last W, drop the rest.
And the benchmarks say that’s enough to cut peak memory by 36–46% and boost throughput by 18–21%. Sometimes the simplest version of an idea is the one worth shipping.
The full code can be found here: https://github.com/czhou578/nanoGPT-inference/blob/main/nanogpt-sliding-window.py
CZ