Benchmarking NanoGPT Inference, Part 2: Teaching The Server To Spend Its Next Forward Pass
This is Part 2 of a series where I benchmark every inference optimization I add to NanoGPT. The goal is not just to make the code faster, but to make each optimization legible: what problem it solves, what metric it helps, and what tradeoff it quietly introduces.
In Part 1, I looked at the first layer of serving mechanics: KV caching, continuous batching, and chunked prefill. In this post, the toy server gets a little more opinionated. Once the obvious caching and batching pieces are in place, NanoGPT starts to look less like a model wrapper and more like a small operating system.
Requests arrive at different times. Some are short, some are long. Some are urgent. Some share a giant prompt prefix. Decode wants steady one-token steps; prefill wants to push big chunks of prompt through the model. The server has one recurring question:
What should the next forward pass be spent on?
That is the organizing question for this second benchmark post. Here I added a few more pieces to my NanoGPT serving toy: priority scheduling, prefix caching, and the beginnings of prefill/decode interleaving.
The headline is not “everything got faster.” The more interesting result is that each feature changes a different part of the serving problem:
- Scheduling decides who gets served first.
- Prefix caching avoids repeating prompt work that the server has already done.
- Interleaving is the glue that lets prefill and decode compete for the same token budget.
These are not independent tricks. They are all different answers to the same question: when the engine has capacity for a little more work, what work should it admit?
The Toy Server
The benchmark uses a very small NanoGPT-style model:
- Model size:
0.056769Mparameters - Context length:
block_size=64 - Benchmark target: serving mechanics, not model quality
Before each benchmark, the model trains briefly. The loss goes down, but the generated samples are still noisy. That is fine here. The model is intentionally tiny because I want the serving behavior to be easy to inspect.
This also means the timings are not production timings. Python overhead, cache bookkeeping, tensor slicing, and scheduler logic are large compared to the actual transformer compute. Whenever a benchmark says “slower,” I read it as: at this toy scale, the overhead is visible. The useful question is whether the mechanism behaves correctly.
With that caveat in mind, let’s start with the most operating-system-like feature: scheduling.
Scheduling: Who Gets The Next Token?
Suppose a long, low-priority batch request arrives first. A moment later, a short interactive request arrives. First-come-first-served has a simple answer: the long request was first, so it keeps the engine.
A scheduler asks a better question: should the urgent request jump the line?
In this benchmark, I compared two policies:
| Policy | Behavior |
|---|---|
FCFS |
Serve requests in arrival order. |
priority |
Serve lower priority-number requests first. If necessary, preempt lower-priority active work. |
The scheduler does not make the transformer faster. It changes the answer to a policy question: when there is room for only one more request, whose token do we buy next?
Scheduling Results
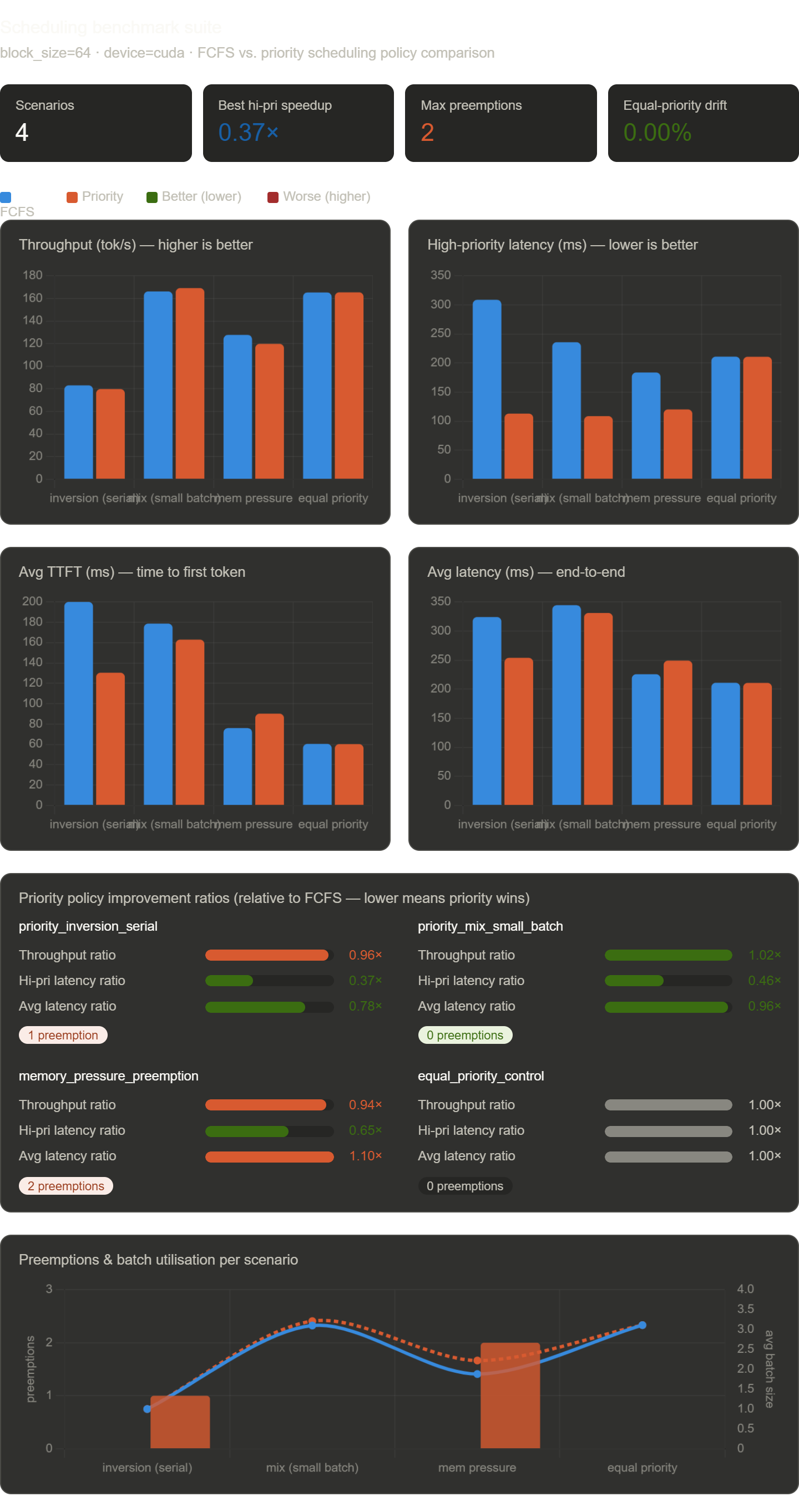
| Case | FCFS Tok/s | Priority Tok/s | Throughput Ratio | FCFS High-Priority Latency | Priority High-Priority Latency | High-Priority Latency Ratio | Preemptions |
|---|---|---|---|---|---|---|---|
priority_inversion_serial |
83.04 | 79.77 | 0.96x | 308.77 ms | 112.88 ms | 0.37x | 1 |
priority_mix_small_batch |
166.15 | 169.10 | 1.02x | 235.69 ms | 108.55 ms | 0.46x | 0 |
memory_pressure_preemption |
127.67 | 119.76 | 0.94x | 183.62 ms | 120.07 ms | 0.65x | 2 |
equal_priority_control |
165.27 | 165.35 | 1.00x | 210.86 ms | 210.66 ms | 1.00x | 0 |
The important column is high-priority latency. In every workload where priorities actually differ, the priority scheduler helps the requests we care about:
| Case | High-Priority Latency Improvement |
|---|---|
priority_inversion_serial |
63.4% lower |
priority_mix_small_batch |
53.9% lower |
memory_pressure_preemption |
34.6% lower |
The control case matters too. When all requests have equal priority, FCFS and priority scheduling produce effectively identical results. That is exactly what should happen: if priority carries no information, the priority key falls back to arrival order.
Priority Inversion
The cleanest example is priority_inversion_serial:
max_batch_size=1
token_budget=12
prefill_chunk_size=10
max_kv_tokens=40
With max_batch_size=1, only one request can be active at a time. FCFS lets the early lower-priority request occupy the engine. Priority scheduling performs one preemption and lets the high-priority request move ahead.
| Metric | FCFS | Priority | Reading |
|---|---|---|---|
| Throughput | 83.04 tok/s | 79.77 tok/s | Priority is slightly slower. |
| Avg TTFT | 199.97 ms | 130.38 ms | First-token responsiveness improves. |
| Avg latency | 323.95 ms | 253.90 ms | Overall average latency improves. |
| High-priority latency | 308.77 ms | 112.88 ms | The important request stops waiting. |
| Low-priority latency | 339.14 ms | 394.92 ms | The lower-priority request pays. |
| Preemptions | 0 | 1 | The win is bought with recompute. |
This is the scheduler tradeoff in miniature. High-priority latency falls to about 37% of the FCFS value. Throughput falls slightly because the preempted request loses its KV cache and has to prefill again later.
That is not a bug. It is the price of this preemption strategy.
When Admission Order Is Enough
In priority_mix_small_batch, priority scheduling cuts high-priority latency from 235.69 ms to 108.55 ms with no preemptions:
max_batch_size=4
token_budget=16
prefill_chunk_size=8
max_kv_tokens=64
This is the most attractive kind of scheduler win. The engine does not throw away any active work. It simply admits requests in a better order, and the high-priority requests finish much earlier. Throughput is essentially unchanged: 166.15 tok/s for FCFS versus 169.10 tok/s for priority.
In other words, sometimes the scheduler does not need a dramatic mechanism. It just needs to stop pretending that arrival order is the same thing as importance.
When Memory Pressure Bites
The sharper case is memory_pressure_preemption:
max_batch_size=3
token_budget=12
prefill_chunk_size=8
max_kv_tokens=32
Here the KV-token budget is tight. Priority scheduling performs two preemptions. High-priority latency still improves, from 183.62 ms to 120.07 ms, but the rest of the metrics get worse:
| Metric | FCFS | Priority |
|---|---|---|
| Throughput | 127.67 tok/s | 119.76 tok/s |
| Avg TTFT | 75.94 ms | 90.15 ms |
| Avg latency | 225.58 ms | 249.03 ms |
| Low-priority latency | 253.56 ms | 335.00 ms |
This is the honest version of priority scheduling. It does not delete waiting time. It moves waiting time onto less important work. Under memory pressure, it can also create extra compute by forcing preempted requests to rebuild their KV state.
For a serving system, that can still be the correct tradeoff. Interactive requests, paid-tier requests, moderation calls, or short latency-sensitive completions may deserve to jump ahead of slow background work. But the scheduler is a policy layer, not a free lunch machine.
Prefix Caching: Memoization For Prompts
KV caching remembers the past of one request. Prefix caching remembers the beginning of many requests.
Imagine every request starts with the same system prompt, tool instructions, or retrieval scaffold:
shared prefix: [system prompt, tool schema, policy text, ...]
unique suffix: [the user's actual question]
Without prefix caching, the server recomputes the shared prefix for every request. With prefix caching, the first request stores KV blocks for the prefix, and later requests load those blocks and only prefill the suffix.
That is the whole idea:
first request:
prefill shared prefix + unique suffix
cache shared prefix blocks
later request:
load shared prefix KV blocks
prefill only unique suffix
In this implementation, the cache is block-based and content-addressed. With prefix_block_size=4, a 16-token shared prefix becomes four cached blocks. The cache uses chained hashes, so a block is identified by both its own tokens and all previous prefix blocks. This prevents the same 4-token sequence from being reused under the wrong prefix.
Prefix Cache Results
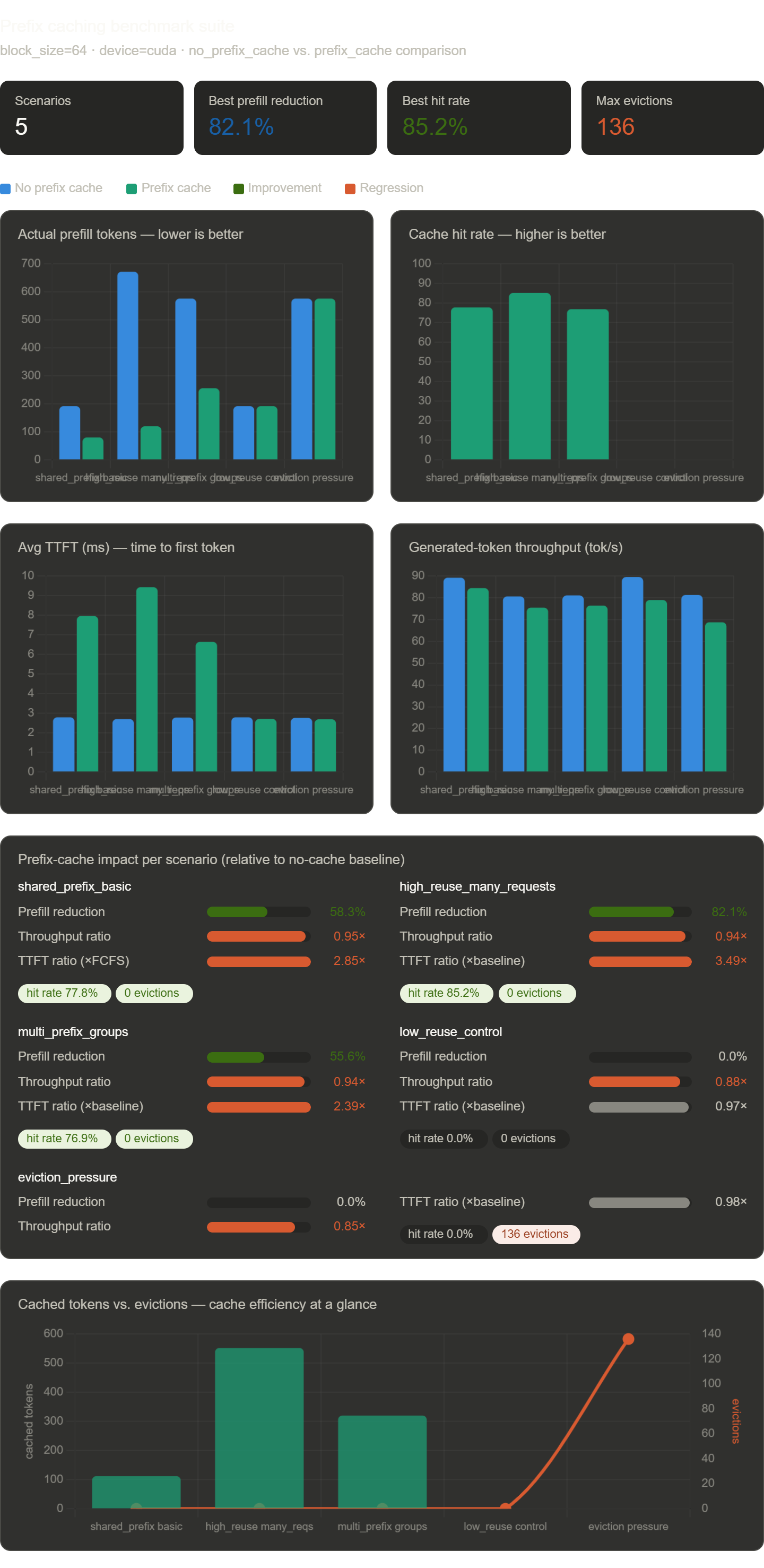
| Case | Requests | Prompt Tokens | Cached Tokens | Actual Prefill | Prefill Reduction | Hit Rate | Throughput Ratio | Evictions |
|---|---|---|---|---|---|---|---|---|
shared_prefix_basic |
8 | 192 | 112 | 80 | 58.3% | 77.8% | 0.95x | 0 |
high_reuse_many_requests |
24 | 672 | 552 | 120 | 82.1% | 85.2% | 0.94x | 0 |
multi_prefix_groups |
24 | 576 | 320 | 256 | 55.6% | 76.9% | 0.94x | 0 |
low_reuse_control |
8 | 192 | 0 | 192 | 0.0% | 0.0% | 0.88x | 0 |
eviction_pressure |
24 | 576 | 0 | 576 | 0.0% | 0.0% | 0.85x | 136 |
The first three rows show the cache doing what it was built to do:
shared_prefix_basicavoids 112 of 192 prompt tokens.high_reuse_many_requestsavoids 552 of 672 prompt tokens.multi_prefix_groupsavoids 320 of 576 prompt tokens.
The strongest case is high_reuse_many_requests. Once the shared prefix is warm, almost every later request avoids most of its prompt prefill. Actual prefill drops from 672 tokens to 120 tokens, an 82.1% reduction.
So mechanically, prefix caching works.
The Catch
The wall-clock numbers go the other way:
| Case | No Cache Gen Tok/s | Prefix Cache Gen Tok/s | Ratio |
|---|---|---|---|
shared_prefix_basic |
89.22 | 84.44 | 0.95x |
high_reuse_many_requests |
80.64 | 75.48 | 0.94x |
multi_prefix_groups |
81.10 | 76.43 | 0.94x |
low_reuse_control |
89.53 | 78.98 | 0.88x |
eviction_pressure |
81.30 | 68.75 | 0.85x |
The cache saves prefill tokens, but the benchmark still gets slower.
This looks contradictory only if we forget how tiny the model is. With 0.056769M parameters and short prompts, prefill compute is cheap. The cache path has to hash tokens, look up blocks, clone KV tensors, slice them, concatenate them, insert new blocks, and sometimes evict old blocks. At this scale, that bookkeeping costs more than the skipped transformer work.
The right conclusion is:
Prefix caching reduces repeated prefill work, but this educational implementation does not yet convert that saved work into faster wall-clock time.
That is still a useful result. It tells us the mechanism is correct and the implementation is overhead-bound.
TTFT Behavior
In a larger serving system, prefix caching often improves TTFT for repeated long prompts. Here it increases TTFT in the shared-prefix cases:
| Case | No Cache Avg TTFT | Prefix Cache Avg TTFT | Ratio |
|---|---|---|---|
shared_prefix_basic |
2.79 ms | 7.96 ms | 2.85x |
high_reuse_many_requests |
2.70 ms | 9.43 ms | 3.49x |
multi_prefix_groups |
2.78 ms | 6.64 ms | 2.39x |
low_reuse_control |
2.79 ms | 2.71 ms | 0.97x |
eviction_pressure |
2.76 ms | 2.69 ms | 0.98x |
The control and eviction rows sit near 1.0x, which suggests the TTFT penalty is tied to the cache-load path, not normal request processing. Again, the toy benchmark is telling us where the overhead lives.
Two Failure Modes
The low_reuse_control row uses unique prompts. The cache fills with blocks, but no later request has the same prefix chain. Cached tokens stay at 0, the hit rate is 0.0%, and throughput drops to 0.88x.
That is the first failure mode:
Prefix caching only helps when traffic actually shares prefixes.
The eviction_pressure row is the second failure mode:
max_cache_blocks=8
num_groups=6
shared_prefix_len=16
prefix_block_size=4
Each shared prefix needs four blocks. Six groups need far more blocks than the cache can hold. The result is 136 evictions, 0 cached tokens, and a throughput ratio of 0.85x.
So the cache also has to be large enough to keep hot prefixes resident. Otherwise it becomes a very elaborate way to do extra bookkeeping.
Interleaving: The Shape Of The Full Loop
Scheduling, batching, and prefix caching all point toward the same serving loop.
At every step, the engine has a token budget. Decode requests are already active and usually cheap: each one wants one more token and already owns KV memory. Prefill requests are bulkier: each one wants to push some prompt chunk through the model before it can start decoding.
Decode-prefill interleaving is the policy that mixes these two kinds of work:
while there is work:
spend some budget on decode tokens for active requests
spend remaining budget on prefill chunks for waiting requests
admit, evict, cache, and reorder according to scheduler policy
The important part is not the pseudocode. It is the pressure it represents. Prefill and decode are both hungry. If prefill gets too much budget, first-token latency for new requests may improve while existing streams stall. If decode gets too much budget, active streams stay smooth while new requests wait to start.
This is why the earlier sections belong together:
- Priority scheduling decides which waiting requests deserve admission.
- Prefix caching reduces the amount of prefill work needed for repeated prompts.
- Interleaving decides how decode and prefill share the next forward pass.
The tiny NanoGPT server is starting to look like a real serving engine because the model call is no longer the whole story. The interesting behavior is now in the queue.
Takeaways
The most useful lesson from this round is that serving optimizations have different objectives.
Priority scheduling did not make the model faster. It made important requests wait less. In the best case, high-priority latency dropped from 308.77 ms to 112.88 ms. Under memory pressure, that same idea cost throughput because preempted requests had to recompute.
Prefix caching avoided repeated prompt work. In the strongest reuse case, actual prefill fell by 82.1%. But the tiny implementation was still slower wall-clock because cache overhead dominated the saved compute.
So the practical mental model is:
KV caching remembers one request. Prefix caching remembers shared prompts. Scheduling decides who gets access. Interleaving decides how prefill and decode coexist.
That is the next layer of LLM inference after “just run the model.” The forward pass is still the expensive primitive, but the serving engine around it decides whether that primitive is spent wisely.
For the full testing code, refer to https://github.com/czhou578/multimodal-inference-visualizer/tree/main/benchmarks
CZ