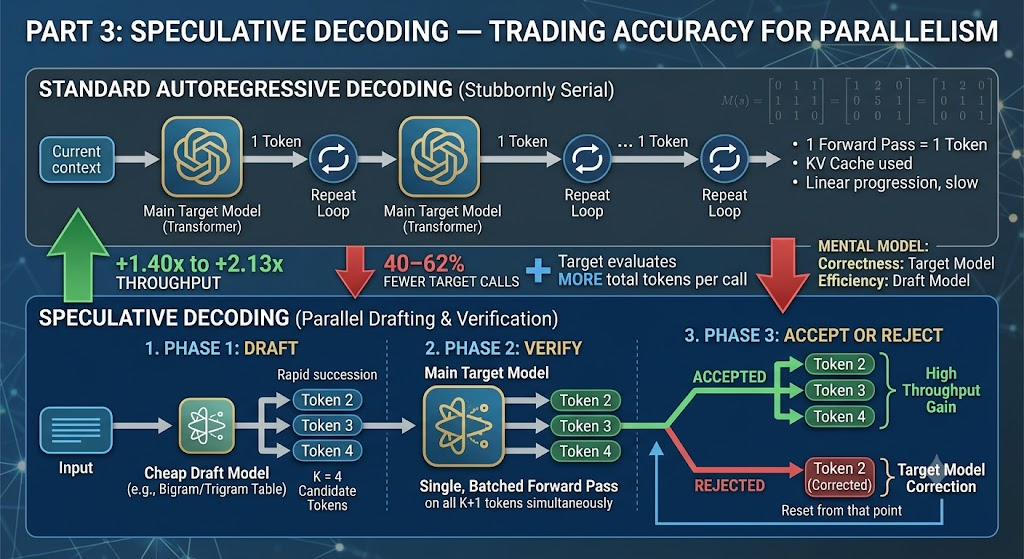
Part 3: Speculative Decoding - Trading Accuracy for Parallelism
Autoregressive decoding is stubbornly serial. Each token depends on the previous one. KV caching removes redundant attention work, but it does not remove the loop: one forward pass, one token, repeat.
Speculative decoding breaks this pattern. A cheap draft model proposes several future tokens. The target model verifies the entire proposed sequence in a single forward pass. When the draft is right, multiple tokens are emitted from one target call. When it is wrong, the target model corrects the first rejected position and continues.
This post benchmarks two draft models - a bigram table and a trigram table - against standard KV-cached decoding on a tiny NanoGPT. The draft models are intentionally primitive. They exist to test the mechanism, not to approximate production quality.
The results demonstrate a consistent pattern:
- Throughput improves by 1.40x to 2.13x across all configurations.
- Target forward calls drop to 40–62% of the KV baseline.
- The target model evaluates more total tokens, not fewer - but packages them into fewer calls.
The core tradeoff is clear: speculative decoding does not reduce the total work the target model performs. It reduces the number of times the target model is invoked.
Setup
All benchmarks use the same model and hardware:
- Model:
0.056769Mparameters - Device: CPU
- Context length:
block_size=64 - Prompt length:
24tokens in every row
The model trains briefly before each benchmark run:
| Step | Train Loss | Validation Loss |
|---|---|---|
| 0 | 4.1800 | 4.1791 |
| 20 | 3.6074 | 3.6479 |
| 40 | 3.3261 | 3.3321 |
| 60 | 3.1051 | 3.1305 |
| 80 | 2.9561 | 2.9651 |
| 100 | 2.8321 | 2.8682 |
| 119 | 2.7759 | 2.7995 |
Generated samples are noisy. That is expected from a tiny character-level model. These benchmarks measure serving mechanics - forward call counts, acceptance rates, verification sizes, throughput - not output quality.
The mechanism
Speculative decoding introduces three phases into the decode loop:
- Draft. A cheap model proposes
Kcandidate tokens. - Verify. The target model scores the current token plus all candidates in one forward pass.
- Accept or reject. Accepted candidates are emitted immediately. On rejection, a corrected token is sampled from the target distribution and the KV cache is trimmed to the accepted prefix.
Standard KV decoding is the degenerate case: K=0, one token per target call, no drafting.
The key metrics:
| Metric | Meaning |
|---|---|
gen_tok/s |
Generated tokens per second. Higher is better. |
target_calls |
Number of target-model forward calls. Fewer is better. |
target_tok |
Total tokens evaluated by the target model. Includes prompt and verification tokens. |
avg_verify |
Average emitted tokens per speculative verification step. Higher means more useful work per call. |
accept |
Fraction of proposed draft tokens accepted. Higher means a better draft. |
avg_lat_ms |
Average request latency. Lower is better. |
Part A: Bigram draft
The simplest possible draft model. It conditions on exactly one token:
P(next_token | current_token)
This is not a neural network. It is a transition-count table built from training data. It puts a hard ceiling on acceptance - bigram statistics are a weak approximation of a transformer - but it makes the benchmark easy to run and easy to reason about.
Bigram results
| Case | Requests | Generated Tokens | K | KV Tok/s | Spec Tok/s | Throughput Ratio | Target Call Ratio | Target Token Ratio | Acceptance |
|---|---|---|---|---|---|---|---|---|---|
k2_bigram_draft |
8 | 128 | 2 | 896.05 | 1379.86 | 1.54x | 0.49x | 1.13x | 63.6% |
k4_bigram_draft |
8 | 128 | 4 | 895.85 | 1549.35 | 1.73x | 0.43x | 1.29x | 48.1% |
k6_bigram_draft |
8 | 128 | 6 | 938.86 | 1616.56 | 1.72x | 0.43x | 1.48x | 34.7% |
k4_noisy_draft |
8 | 128 | 4 | 957.25 | 1707.07 | 1.78x | 0.40x | 1.26x | 52.2% |
longer_outputs_k4 |
6 | 144 | 4 | 893.93 | 1589.45 | 1.78x | 0.41x | 1.40x | 46.2% |
Every configuration is faster than the KV baseline. Average throughput ratio: approximately 1.71x.
The shape of the speedup
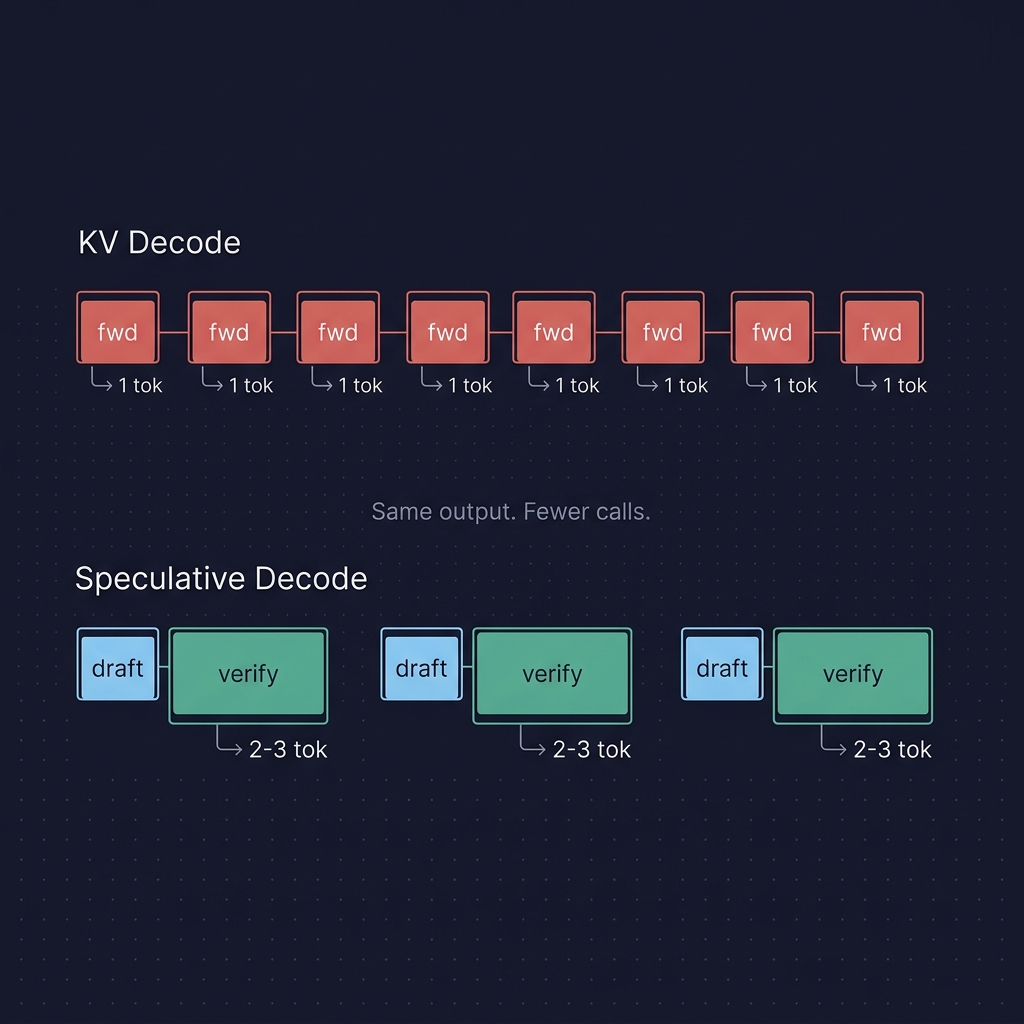
The speedup does not come from doing less work. It comes from doing work differently.
Normal KV decoding runs one forward pass per generated token:
target forward → 1 token
target forward → 1 token
target forward → 1 token
Speculative decoding groups work:
draft proposes K tokens
target verifies K+1 positions in one forward
emit several tokens if accepted
Each verification forward is larger, but there are far fewer of them. Target forward calls drop from 128 to 51–63 for the 8-request, 128-token workloads.
Meanwhile, total target tokens evaluated increase:
| Case | KV Target Tokens | Spec Target Tokens | Increase |
|---|---|---|---|
k2_bigram_draft |
312 | 354 | +13% |
k4_bigram_draft |
312 | 401 | +29% |
k6_bigram_draft |
312 | 461 | +48% |
k4_noisy_draft |
312 | 392 | +26% |
longer_outputs_k4 |
282 | 394 | +40% |
On this CPU benchmark, reducing call overhead and eliminating serial stepping outweighs the additional token evaluations.
Speculation depth
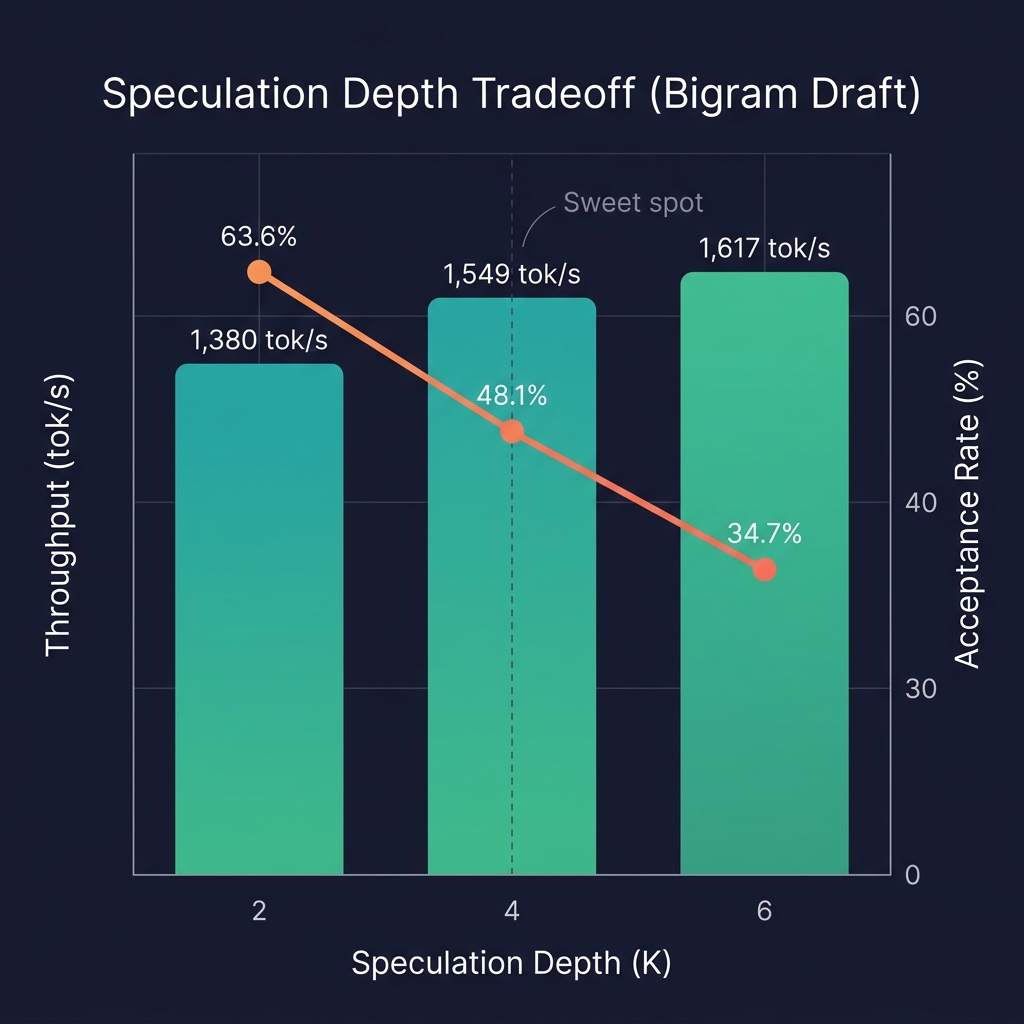
The three clean bigram rows isolate the effect of K:
| K | Spec Tok/s | Target Calls | Target Tokens | Avg Verify | Acceptance |
|---|---|---|---|---|---|
| 2 | 1379.86 | 63 | 354 | 2.18 | 63.6% |
| 4 | 1549.35 | 55 | 401 | 2.55 | 48.1% |
| 6 | 1616.56 | 55 | 461 | 2.55 | 34.7% |
K=2 → K=4 is a clean win: throughput rises, target calls fall, and each verification step emits more useful tokens.
K=4 → K=6 is diminishing. Throughput increases marginally. Target calls do not improve. Target tokens jump. Acceptance drops sharply from 48.1% to 34.7%. The draft model cannot predict reliably six tokens ahead.
K=4 is the balanced setting in this benchmark. K=6 asks the draft model to predict farther than its statistics support.
Acceptance rate
Acceptance does not need to be perfect for speculative decoding to help.
| Case | Draft Tokens Proposed | Accepted | Acceptance |
|---|---|---|---|
k2_bigram_draft |
107 | 68 | 63.6% |
k4_bigram_draft |
162 | 78 | 48.1% |
k6_bigram_draft |
222 | 77 | 34.7% |
k4_noisy_draft |
157 | 82 | 52.2% |
longer_outputs_k4 |
197 | 91 | 46.2% |
The k4_bigram_draft row accepts less than half of its draft tokens and still achieves 1.73x throughput. Even partial acceptance emits more than one token per verification step.
A stronger draft model would raise acceptance, reduce wasted verification work, and allow larger K values to remain useful.
Bonus and resampled tokens
Two counters track how verification steps conclude:
| Case | Bonus Tokens | Resampled Tokens |
|---|---|---|
k2_bigram_draft |
28 | 24 |
k4_bigram_draft |
13 | 29 |
k6_bigram_draft |
6 | 37 |
k4_noisy_draft |
13 | 25 |
longer_outputs_k4 |
13 | 34 |
Bonus tokens occur when every candidate in a verification step is accepted. The target model has already computed the next distribution, so one additional token can be sampled for free.
Resampled tokens occur on rejection. A corrected token is sampled from an adjusted target distribution, and the remaining candidates in that batch are discarded.
Shorter chains (K=2) produce more bonus tokens. Longer chains (K=6) produce more resampled tokens. This is the same tradeoff restated: deeper speculation increases the chance of rejection.
Latency
| Case | KV Avg Latency | Spec Avg Latency | Reduction |
|---|---|---|---|
k2_bigram_draft |
17.86 ms | 11.59 ms | 35.1% |
k4_bigram_draft |
17.86 ms | 10.33 ms | 42.2% |
k6_bigram_draft |
17.04 ms | 9.90 ms | 41.9% |
k4_noisy_draft |
16.71 ms | 9.37 ms | 43.9% |
longer_outputs_k4 |
26.85 ms | 15.10 ms | 43.8% |
Latency improvement tracks target call reduction directly. Fewer decode iterations means each request finishes sooner.
TTFT improves only slightly - both methods perform the same prompt prefill before emitting the first token. Speculative decoding is a decode-phase optimization.
Draft noise
The k4_noisy_draft row blends the bigram distribution with uniform noise (draft_noise=0.5). It is the fastest 128-token row at 1707.07 tok/s.
This result should not be over-interpreted. With only 8 requests and 128 generated tokens, sampling variance can produce favorable outliers. The conservative conclusion:
The K=4 speculative path is robust to a noisier draft distribution. Even with degraded draft quality, the mechanism still reduces target calls and improves throughput.
Longer outputs
The longer_outputs_k4 row increases each request from 16 to 24 generated tokens. Speculative decoding is a decode-phase optimization, so longer outputs provide more opportunities for the mechanism to pay off.
| Metric | KV | Speculative |
|---|---|---|
| Throughput | 893.93 tok/s | 1589.45 tok/s |
| Target calls | 144 | 59 |
| Avg latency | 26.85 ms | 15.10 ms |
The speedup holds at 1.78x. More decode steps means more chances to collapse serial target forwards into verification batches.
Forward time
| Case | KV Forward Time | Spec Forward Time | Reduction |
|---|---|---|---|
k2_bigram_draft |
0.1364 s | 0.0807 s | 40.8% |
k4_bigram_draft |
0.1364 s | 0.0703 s | 48.5% |
k6_bigram_draft |
0.1302 s | 0.0663 s | 49.1% |
k4_noisy_draft |
0.1274 s | 0.0635 s | 50.2% |
longer_outputs_k4 |
0.1535 s | 0.0764 s | 50.2% |
The speculative path substantially reduces measured target-forward time, confirming that the speedup is not merely an artifact of shifting work outside the measurement window.
Part B: Trigram draft
The trigram draft extends the bigram by conditioning on two tokens:
P(next_token | token_{t-2}, token_{t-1})
It is still table-based, still extremely cheap compared with a neural draft, but it has more local context than the bigram. The question: does a slightly richer draft change the shape of the benchmark?
Trigram results
| Case | Requests | Generated Tokens | K | KV Tok/s | Trigram Spec Tok/s | Throughput Ratio | Target Call Ratio | Target Token Ratio | Acceptance |
|---|---|---|---|---|---|---|---|---|---|
k2_trigram_draft |
8 | 128 | 2 | 545.44 | 1162.72 | 2.13x | 0.62x | 1.29x | 39.9% |
k4_trigram_draft |
8 | 128 | 4 | 877.26 | 1232.47 | 1.40x | 0.54x | 1.52x | 28.1% |
k6_trigram_draft |
8 | 128 | 6 | 959.98 | 1361.51 | 1.42x | 0.48x | 1.70x | 25.7% |
k4_noisy_trigram |
8 | 128 | 4 | 941.86 | 1318.78 | 1.40x | 0.51x | 1.47x | 31.9% |
longer_outputs_k4_trigram |
6 | 144 | 4 | 958.46 | 1431.82 | 1.49x | 0.47x | 1.58x | 33.5% |
Every row improves over the KV baseline. Average throughput ratio: approximately 1.57x.
One caveat: the k2_trigram_draft KV baseline is significantly slower than other KV baselines in this section. Its 2.13x ratio is partly an artifact of a slow baseline, not purely a stronger draft.
Target call reduction
| Case | KV Target Calls | Trigram Target Calls | Reduction |
|---|---|---|---|
k2_trigram_draft |
128 | 79 | 38.3% |
k4_trigram_draft |
128 | 69 | 46.1% |
k6_trigram_draft |
128 | 61 | 52.3% |
k4_noisy_trigram |
128 | 65 | 49.2% |
longer_outputs_k4_trigram |
144 | 68 | 52.8% |
The same pattern holds. Each verification step can emit one or more tokens - even when many candidates are rejected, a corrected token is still produced.
The cost: more target tokens
| Case | KV Target Tokens | Trigram Target Tokens | Increase |
|---|---|---|---|
k2_trigram_draft |
312 | 401 | +28.5% |
k4_trigram_draft |
312 | 474 | +51.9% |
k6_trigram_draft |
312 | 529 | +69.6% |
k4_noisy_trigram |
312 | 459 | +47.1% |
longer_outputs_k4_trigram |
282 | 445 | +57.8% |
The exchange is explicit: verification evaluates extra candidate positions, but those positions are batched into fewer, larger forward calls. On this CPU benchmark, fewer calls still wins.
Speculation depth (trigram)
| K | Spec Tok/s | Target Calls | Target Tokens | Avg Verify | Acceptance |
|---|---|---|---|---|---|
| 2 | 1162.72 | 79 | 401 | 1.69 | 39.9% |
| 4 | 1232.47 | 69 | 474 | 1.97 | 28.1% |
| 6 | 1361.51 | 61 | 529 | 2.26 | 25.7% |
K=6 achieves the highest absolute throughput among clean trigram runs, but at the cost of the most extra target-token work and the lowest acceptance. On a larger model or different hardware, that extra verification work could become the bottleneck.
Larger K reduces serial target calls, but weak later predictions create increasingly wasted candidate work.
Acceptance rate (trigram)
| Case | Draft Tokens Proposed | Accepted | Acceptance |
|---|---|---|---|
k2_trigram_draft |
138 | 55 | 39.9% |
k4_trigram_draft |
221 | 62 | 28.1% |
k6_trigram_draft |
284 | 73 | 25.7% |
k4_noisy_trigram |
210 | 67 | 31.9% |
longer_outputs_k4_trigram |
239 | 80 | 33.5% |
Trigram acceptance rates are modest. Most proposed tokens are rejected. The mechanism still produces speedups because even partial acceptance emits more than one token per verification, and rejection still produces a corrected output token.
The low acceptance confirms that a trigram table is a weak approximation of the target model. A neural draft would likely improve acceptance substantially, enabling larger K values and reducing wasted verification work.
Bonus and resampled tokens (trigram)
| Case | Bonus Tokens | Resampled Tokens |
|---|---|---|
k2_trigram_draft |
15 | 50 |
k4_trigram_draft |
4 | 54 |
k6_trigram_draft |
2 | 45 |
k4_noisy_trigram |
7 | 46 |
longer_outputs_k4_trigram |
6 | 52 |
K=2 produces the most bonus tokens. K=6 produces the fewest. Resampling is common across all rows, reflecting the modest draft quality.
Latency (trigram)
| Case | KV Avg Latency | Trigram Avg Latency | Reduction |
|---|---|---|---|
k2_trigram_draft |
29.33 ms | 13.76 ms | 53.1% |
k4_trigram_draft |
18.24 ms | 12.98 ms | 28.8% |
k6_trigram_draft |
16.67 ms | 11.75 ms | 29.5% |
k4_noisy_trigram |
16.99 ms | 12.13 ms | 28.6% |
longer_outputs_k4_trigram |
25.04 ms | 16.76 ms | 33.1% |
Latency improves because each request needs fewer target-model iterations.
TTFT improves slightly but is not the primary benefit - both methods perform the same prompt prefill before emitting the first token.
Draft noise (trigram)
The k4_noisy_trigram row adds draft_noise=0.5 to the K=4 trigram. It outperforms the clean K=4 row in this single run, but the likely explanation is sampling variance.
The K=4 trigram speculative path is robust to a noisier draft distribution.
Forward time (trigram)
| Case | KV Forward Time | Trigram Forward Time | Reduction |
|---|---|---|---|
k2_trigram_draft |
0.2227 s | 0.0947 s | 57.5% |
k4_trigram_draft |
0.1387 s | 0.0871 s | 37.2% |
k6_trigram_draft |
0.1269 s | 0.0774 s | 39.0% |
k4_noisy_trigram |
0.1295 s | 0.0819 s | 36.8% |
longer_outputs_k4_trigram |
0.1430 s | 0.0839 s | 41.3% |
The speculative path reduces measured target-forward time despite evaluating more target tokens, because it uses far fewer separate calls.
Bigram vs. trigram
The two draft models demonstrate the same mechanism with different trade-off profiles:
| Draft | Throughput Range | Acceptance Range | Target Call Range |
|---|---|---|---|
| Bigram | 1.54x – 1.78x | 34.7% – 63.6% | 0.40x – 0.49x |
| Trigram | 1.40x – 2.13x | 25.7% – 39.9% | 0.47x – 0.62x |
The bigram achieves higher acceptance rates across the board. The trigram’s additional context does not translate into better acceptance in these runs - likely because the trigram table is smoothed and the tiny model’s distributions are noisy enough that a two-token context window does not provide a meaningful advantage over a one-token window.
Both drafts confirm the central finding: speculative decoding produces speedups even with crude drafts and low acceptance, because reducing the number of serial target calls is the dominant lever.
Caveats
These benchmarks measure mechanism behavior at toy scale. Several factors limit direct extrapolation to production:
- Tiny model. At
0.056769Mparameters, Python and PyTorch overhead are large relative to model compute. - CPU-only. GPU behavior can differ, especially for larger verification batches.
- Table-based drafts. Neither the bigram nor trigram approximates the target model well. A neural draft would change the acceptance-throughput tradeoff substantially.
- Low acceptance. Most proposed tokens are rejected. Better drafts would shift the balance.
- Small sample sizes. Most rows generate only 128 tokens. Stochastic variation can affect results.
- Single-run. Multi-seed averaging would make noise-related observations more reliable.
- No quality evaluation. Speculative decoding preserves the target model’s output distribution by construction, but this benchmark does not verify output quality.
Summary
Speculative decoding converts a serial autoregressive loop into a draft-verify pattern that can emit multiple tokens per target call.
The mechanism works even with primitive drafts:
- Target calls drop to 40–62% of the KV baseline.
- Throughput improves in every configuration tested.
- Latency drops because each request needs fewer decode iterations.
- Longer decode workloads benefit more, since speculation has more opportunities to collapse serial forwards into verification batches.
The limiting factor is draft quality. Acceptance rates range from 25.7% to 63.6% with these table-based drafts. A stronger draft model - even a small neural one - would raise acceptance, reduce wasted verification tokens, and make deeper speculation (K > 4) more effective.
The practical mental model:
The target model still controls correctness. The draft model controls efficiency. Speculative decoding is a scheduling optimization: it changes the shape of the decode loop without changing the output distribution.
For the full testing code, refer to https://github.com/czhou578/multimodal-inference-visualizer/tree/main/benchmarks
CZ