NanoGPT - Correctness Tests for an Inference Engine
Performance optimizations are easy to benchmark and easy to get wrong. A KV cache that silently drops a position. A batching path that transposes logits. A speculative decoder that accepts one too many tokens. These bugs produce plausible-looking output with slightly different distributions - the kind of divergence that throughput numbers never catch.
This post walks through ten correctness tests for the NanoGPT inference engine. Each test isolates one optimization and proves it produces identical output to the simplest possible baseline. The strategy is always the same: run the fast path, run the slow path, compare logits or tokens under deterministic (argmax) decoding.
Every optimization in the engine - KV caching, continuous batching, paged attention, prefix caching, chunked prefill, speculative decoding, and interleaved scheduling - has a corresponding equivalence test.
The testing pattern
Each test follows a common structure:
- Baseline. Run the simplest version of the operation - typically a single forward pass over the full sequence with no caching.
- Optimized path. Run the same operation through the optimization under test.
- Compare. Assert that logits or generated tokens match exactly (within floating-point tolerance).
All tests use greedy (argmax) decoding. This eliminates RNG sensitivity - any divergence between the two paths is a real bug, not sampling noise.
def _greedy_token(logits):
"""Argmax over last-position logits → single token id."""
return logits[0, -1, :].argmax().item()
logits has shape (batch=1, seq_len, vocab_size). Index [0, -1, :] grabs the logit vector at the last sequence position of the first (only) batch element - this is the distribution over next tokens. .argmax() selects the highest-probability token deterministically, and .item() converts the scalar tensor to a Python int.
A shared helper handles greedy decode loops:
def _greedy_decode(model, past_kvs, last_token, num_steps, device):
"""Decode num_steps tokens greedily (argmax), return token list."""
generated = []
for _ in range(num_steps):
cache_len = past_kvs[0][0][0].shape[1]
inp = torch.tensor([[last_token]], dtype=torch.long, device=device)
pos = torch.tensor([[cache_len]], dtype=torch.long, device=device)
logits, _, past_kvs = model(inp, pos=pos, past_kvs=past_kvs)
last_token = _greedy_token(logits)
generated.append(last_token)
return generated, past_kvs
This drives the standard incremental decode loop. past_kvs[0][0][0].shape[1] reads the KV cache length from the first layer, first head, first element (key tensor) - the sequence length dimension tells the model what position the next token occupies. inp is shaped (1, 1) - a single token for a single batch element. pos is [[cache_len]] because the new token’s absolute position equals the number of tokens already in the cache. The model returns updated past_kvs with the new token’s KV appended, so each iteration the cache grows by one.
Test 1: Full recompute == KV-cached incremental
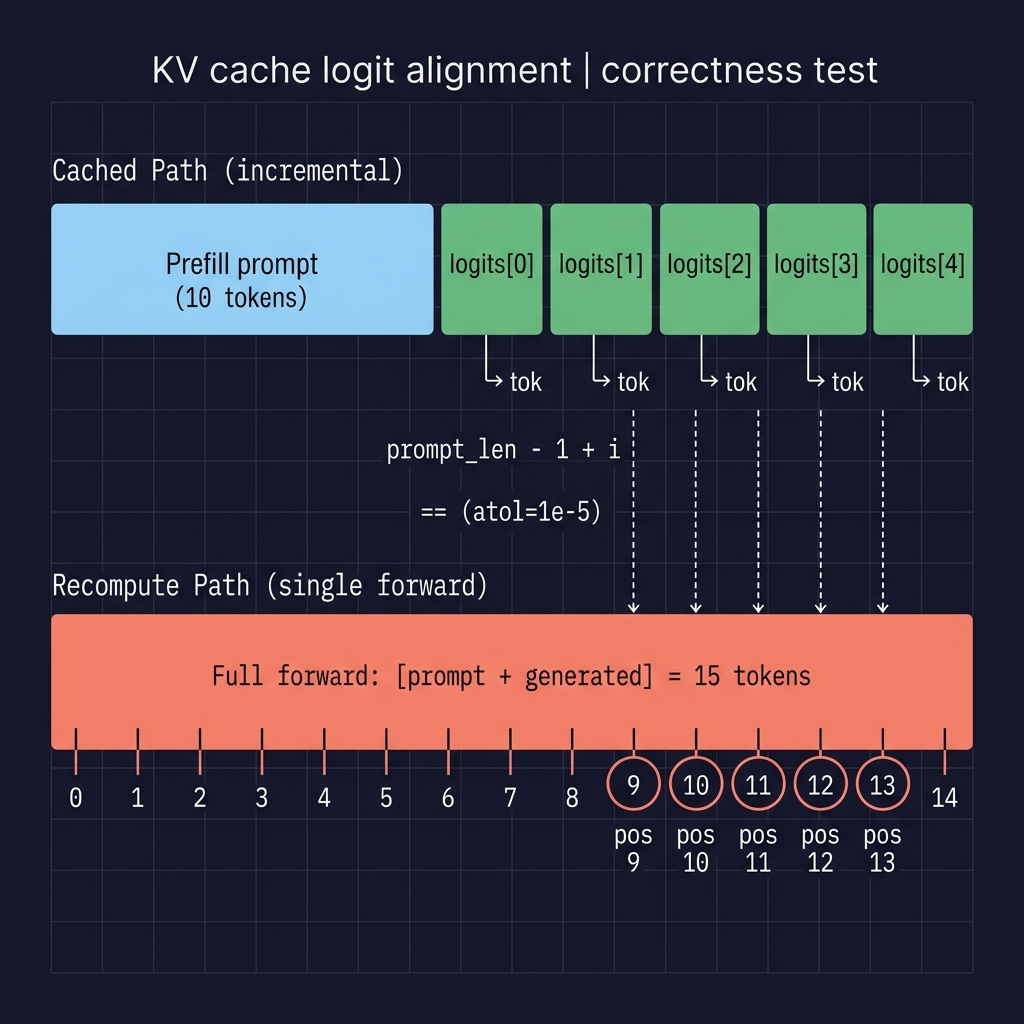
The most fundamental equivalence. If the KV cache is implemented correctly, decoding token-by-token with a growing cache must produce the same logits as a single forward pass over the entire sequence.
Baseline: Prefill a prompt, decode N tokens with the KV cache, save each step’s logits.
Recompute: Concatenate the prompt and all decoded tokens into one sequence. Run a single forward pass. Extract logits at each decode position.
# Cached path
logits, _, past_kvs = model(prompt_t, pos=positions)
cached_logits = [logits[0, -1, :].clone()]
for _ in range(num_decode_steps - 1):
cache_len = past_kvs[0][0][0].shape[1]
inp = torch.tensor([[generated[-1]]], dtype=torch.long, device=device)
pos = torch.tensor([[cache_len]], dtype=torch.long, device=device)
logits, _, past_kvs = model(inp, pos=pos, past_kvs=past_kvs)
cached_logits.append(logits[0, -1, :].clone())
The first call processes the entire prompt in one forward pass, returning logits for every position and a populated KV cache. logits[0, -1, :].clone() captures the logit vector at the last prompt position - this is the distribution that predicts the first generated token. The .clone() is critical: without it, the tensor could be overwritten by the next forward call. Each subsequent iteration feeds one new token and gets one new logit vector, building a list of per-step logits.
# Recompute path
full_seq = prompt + generated
full_logits, _, _ = model(torch.tensor([full_seq]), pos=full_positions)
# Compare at each decode position
for i in range(len(cached_logits)):
assert torch.allclose(cached_logits[i], full_logits[0, prompt_len - 1 + i, :], atol=1e-5)
The recompute path concatenates the original prompt with all generated tokens and runs one forward pass with no cache. The model sees the complete context and produces logits at every position. The comparison uses torch.allclose with atol=1e-5 to account for floating-point differences between the two computation orders (cache-appended vs. single-pass).
The comparison index is prompt_len - 1 + i, not prompt_len + i. In the full forward pass, position prompt_len - 1 predicts the first generated token. This off-by-one is easy to get wrong - the test catches it.
Test 2: Unbatched == Continuously batched
Continuous batching packs multiple requests into a single forward call using _stack_kvs / _unstack_kvs. This test verifies that batching does not corrupt individual request outputs.
Baseline: Decode three requests individually, one at a time.
Batched: Prefill each request individually (to build separate KV caches), then decode all three in batched forward passes using stacked KV tensors.
# Batched decode loop
for _ in range(decode_steps - 1):
stacked = _stack_kvs(all_kvs)
inp = torch.tensor([[t] for t in last_tokens], dtype=torch.long, device=device)
pos = torch.full((num_requests, 1), cache_len, dtype=torch.long, device=device)
logits, _, new_stacked = model(inp, pos=pos, past_kvs=stacked)
all_kvs = _unstack_kvs(new_stacked)
_stack_kvs(all_kvs) takes a list of per-request KV caches (each with shape (1, cache_len, head_size) per head per layer) and stacks them along the batch dimension to produce tensors of shape (num_requests, cache_len, head_size). inp is shaped (num_requests, 1) - one token per request, stacked vertically. pos is (num_requests, 1) filled with cache_len - every request has the same position because they all started with prompts of equal length and have decoded the same number of steps.
After the forward pass, _unstack_kvs splits the batched cache back into per-request caches. This round-trip - stack, forward, unstack - must preserve each request’s KV entries without any cross-contamination between rows.
last_tokens = []
for i in range(num_requests):
token = logits[i, -1, :].argmax().item()
batched_tokens[i].append(token)
last_tokens.append(token)
Each request’s logits are indexed by row i in the batch dimension. logits[i, -1, :] extracts the last-position logits for request i. Under argmax, every request must produce the same token sequence whether decoded alone or in a batch. Any mismatch indicates a bug in KV stacking, position computation, or logit indexing.
Test 3: Contiguous KV == Paged KV
Paged attention stores KV entries in a block pool instead of a contiguous tensor. Each request maintains a block table mapping logical positions to physical blocks.
This test decodes with both a normal contiguous cache and a paged cache, then compares tokens.
The test sweeps multiple prompt lengths (3, 4, 5, 7, 8) to stress block boundaries. With a block size of 4, prompts of length 3, 5, and 7 land mid-block, while 4 and 8 land exactly on boundaries. Off-by-one errors in num_filled_slots // page_block_size only surface when allocations cross these edges.
# Paged path: gather KV from pool, decode, write new KV back
for _ in range(decode_steps - 1):
if num_filled % page_block_size == 0:
block_table.append(allocator.allocate_one())
gathered = []
for layer_idx in range(n_layer):
layer_kv = []
for head_idx in range(n_head):
k, v = _gather_paged_kv(pool, req_obj, page_block_size, layer_idx, head_idx)
layer_kv.append((k, v))
gathered.append(layer_kv)
logits_p, _, new_kvs = model(inp, pos=p, past_kvs=gathered)
# Write only the new token's KV back to pool
for layer_idx in range(n_layer):
for head_idx, (k, v) in enumerate(new_kvs[layer_idx]):
phys = block_table[num_filled // page_block_size]
slot = num_filled % page_block_size
pool.k_pool[(layer_idx, head_idx)][phys, slot, :] = k[0, -1, :]
pool.v_pool[(layer_idx, head_idx)][phys, slot, :] = v[0, -1, :]
Each decode step has three phases. Block allocation: when num_filled is exactly divisible by page_block_size, the current block is full and a new one must be allocated. Gather: _gather_paged_kv walks the block table, reads physical blocks from the pool in logical order, and assembles a contiguous KV tensor the model can consume. The req_obj carries the block table and fill count so the gather function knows which blocks to read and how many slots are valid. Write-back: after the forward pass, the model returns new_kvs containing the full cache (gathered input + new token). Only the last position (k[0, -1, :]) is the new entry - the rest are copies of what was gathered. The physical block and slot within that block are computed via num_filled // page_block_size and num_filled % page_block_size.
The gather-decode-write cycle exercises the full paged attention path. If any block mapping is wrong, the gathered KV will contain stale or misaligned entries, and the argmax tokens will diverge.
Test 4: Prefix-cached == Normal prefill
Prefix caching avoids re-computing shared prompt prefixes across requests. The first request prefills the full prompt and commits KV blocks to a hash-indexed cache. Subsequent requests with the same prefix load those blocks and only prefill the unique suffix.
This test builds three prompts that share a 12-token prefix with different 4-token suffixes:
prefix = torch.randint(0, vocab_size, (shared_prefix_len,)).tolist()
suffixes = [torch.randint(0, vocab_size, (unique_suffix_len,)).tolist() for _ in range(3)]
prompts = [prefix + s for s in suffixes]
torch.randint generates random token IDs. All three prompts share the same prefix list, so their first 12 tokens are identical. Each gets a different random suffix, making the final 4 tokens unique. This setup guarantees that requests 1 and 2 should hit the prefix cache populated by request 0.
Baseline: Full prefill for each prompt. No caching.
Cached: Request 0 populates the prefix cache. Requests 1 and 2 hit it, loading cached KV blocks and prefilling only the suffix.
_load_cached_prefix(req, block_cache, prefix_block_size)
start = req.prefill_cursor
idx = torch.tensor([prompt[start:end]], dtype=torch.long, device=device)
pos = torch.arange(start, end, dtype=torch.long, device=device).unsqueeze(0)
logits, _, new_kvs = model(idx, pos=pos, past_kvs=req.past_kvs)
_commit_completed_blocks(req, block_cache, prefix_block_size)
_load_cached_prefix looks up the request’s prompt tokens in the hash-indexed block cache. If matching blocks exist, it loads their KV entries into req.past_kvs and advances req.prefill_cursor past the cached portion. For request 0, nothing is cached yet, so prefill_cursor stays at 0 and the full prompt is prefilled. For requests 1 and 2, the shared prefix blocks are loaded from cache.
start = req.prefill_cursor is the key variable - it tells us where the cache left off. prompt[start:end] slices only the uncached suffix tokens. pos uses torch.arange(start, end) because each token needs its correct absolute position, not a position relative to the suffix start. The model receives past_kvs=req.past_kvs which already contains the cached prefix KV, so the suffix attention can attend to the full prefix context.
_commit_completed_blocks writes the newly computed KV blocks back to the cache so future requests can reuse them.
The test also verifies that requests after the first actually load cached blocks (req.cached_prefix_tokens > 0). A cache miss on requests 1–2 would mean the caching path is silently broken, even if the outputs happen to match.
Test 5: Speculative greedy == Autoregressive greedy
Under argmax decoding, speculative decoding must produce the exact same tokens as simple autoregressive decoding, regardless of draft quality.
The reasoning is short. When the draft matches the target’s argmax, the target probability is 1 and the acceptance probability is ≥ 1 - always accept. When the draft does not match, the target probability for the draft token is 0 - always reject. On rejection, resampling from max(0, target - draft) reduces to sampling from the target distribution, whose argmax is the target’s argmax. Accept/reject is a no-op under greedy.
This test implements the speculative verify loop inline - not imported from the runner - to avoid masking bugs in the runner itself:
for i, draft_tok in enumerate(candidates):
target_argmax = v_logits[0, i, :].argmax().item()
if draft_tok == target_argmax:
accepted.append(draft_tok)
else:
accepted.append(target_argmax)
break
v_logits has shape (1, K+1, vocab_size) - the target model scored the current token plus all K candidates in one forward pass. v_logits[0, i, :] is the target’s logit distribution at verification position i, which predicts what token should follow the first i candidates. If the draft token matches the target’s argmax at that position, it is accepted and we move to the next candidate. On the first mismatch, the target’s argmax replaces the draft token and the loop breaks - all subsequent candidates are discarded because they were conditioned on the wrong token.
Both bigram and trigram draft models are tested. Three prompts, eight decode tokens each. Any token-level mismatch is a bug in the verify loop, the KV trim, or the rolling context update.
Test 6: Speculative distribution ≈ Target distribution (χ²)
Test 5 proves correctness under argmax. This test addresses the harder question: does the accept/reject algorithm preserve the target model’s sampling distribution?
The test generates 2,000 single tokens from the same prompt via two paths:
- Autoregressive: Sample directly from
softmax(logits / temperature). - Speculative: Draft one candidate from the trigram model, accept/reject against the target distribution, resample on rejection from
max(0, target - draft).
Only one token is generated per trial. This isolates the accept/reject math from RNG-consumption differences that would accumulate over multi-token sequences.
# Accept/reject against the known target distribution
q = draft_probs[draft_tok].clamp_min(1e-12)
p = target_dist[draft_tok]
accept_prob = (p / q).clamp(max=1.0)
draw = torch.rand((), device=device, generator=gen)
if draw.item() < accept_prob.item():
output_token = draft_tok
else:
adjusted = torch.clamp(target_dist - draft_probs, min=0)
adjusted = adjusted / adjusted.sum()
output_token = torch.multinomial(adjusted, 1, generator=gen).item()
q is the draft model’s probability for the proposed token, clamped above zero to avoid division by zero. p is the target model’s probability for the same token. The acceptance probability is p/q, clamped at 1.0 - if the target is more likely than the draft predicted, always accept. draw is a uniform random number from [0, 1).
On acceptance, the output is the draft token. On rejection, the code computes an adjusted distribution: target - draft, clamped at zero and renormalized. This is the key insight from the speculative decoding paper - sampling from max(0, target - draft) on rejection ensures the combined accept/reject procedure produces samples from the exact target distribution. torch.multinomial draws one sample from this adjusted distribution.
The two histograms are compared with a chi-squared test. Only bins with expected count > 5 are included (standard practice to avoid inflated χ² from sparse bins). The test runs three independent seeds and requires at least two to pass at p > 0.01, tolerating the inherent ~1% false-positive rate of the chi-squared test.
The trigram draft is used specifically because it has low acceptance and produces many rejections - a harder stress test for the resampling path.
Test 7: KV cache trim consistency
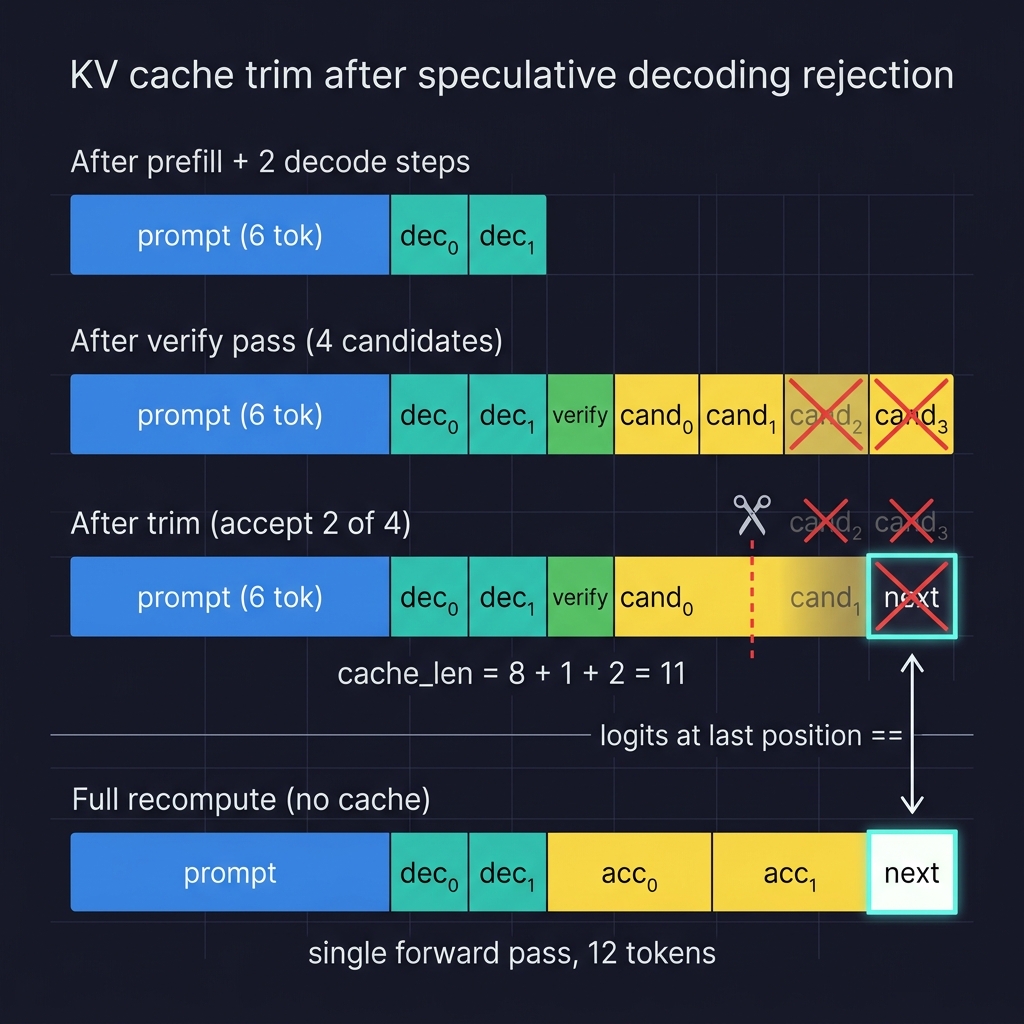
Speculative decoding needs to trim the KV cache after rejection. If 2 of 4 draft tokens are accepted, the cache must discard the KV entries for positions 3 and 4 but keep everything through position 2.
This test builds a cache through a controlled sequence:
- Prefill a prompt.
- Decode 2 tokens greedily.
- Run a verify pass with 4 random draft candidates.
- “Accept” only 2 of 4 - trim the cache using
_trim_kv_cache. - Decode 1 more token from the trimmed cache →
logits_A. - Full recompute of
(prompt + 2 decoded + 2 accepted + next)with no cache →logits_B. - Assert
logits_A ≈ logits_B.
trimmed = _trim_kv_cache(
new_kvs,
cache_len_before_verify=cache_len_before,
keep_new_tokens=1 + accept_count,
)
# Verify shape
expected_cache_len = cache_len_before + 1 + accept_count
actual_cache_len = trimmed[0][0][0].shape[1]
new_kvs is the full cache after the verify forward pass - it contains KV entries for the prompt, 2 decoded tokens, the verify token, and all 4 candidates. _trim_kv_cache slices each KV tensor to keep only the first cache_len_before + 1 + accept_count positions. cache_len_before is the cache length before the verify step (prompt + 2 decoded). 1 + accept_count accounts for the verify token itself plus the accepted candidates. The rejected candidates’ KV entries are discarded.
The shape check verifies the trim cut at the right position. But shape alone is insufficient - if _trim_kv_cache kept the right number of positions but with corrupted values (e.g., from an off-by-one in the slice indices), the shape would pass while the logits would fail. That is why the test also decodes one more token from the trimmed cache and compares against a full recompute.
Test 8: Draft model distribution sanity
A lightweight test that does not need the transformer model at all. It verifies that the bigram and trigram draft models produce valid probability distributions.
Known distribution check: Build a trigram model from the corpus [0, 1, 2, 0, 1, 2, 0, 1, 2]. After context (0, 1), token 2 should have probability > 0.5 (it appeared 2 out of 2 times, plus smoothing).
Normalization check: For a 20-token vocabulary, verify that get_probs(prev, cur).sum() ≈ 1.0 for every sampled (prev, cur) pair in both the trigram and bigram models.
for prev in range(0, 20, 5):
for cur in range(0, 20, 5):
s = tri_big.get_probs(prev, cur).sum().item()
assert abs(s - 1.0) < 1e-5
get_probs(prev, cur) returns a tensor of shape (vocab_size,) - the trigram model’s probability distribution over the next token given the two-token context (prev, cur). The loop samples every 5th token pair (range(0, 20, 5)) to cover a representative grid without testing all 400 combinations. .sum().item() should equal 1.0 for any valid probability distribution. The tolerance 1e-5 accommodates floating-point rounding from the Laplace smoothing and normalization arithmetic.
This catches Laplace smoothing bugs, normalization errors after temperature scaling, and accidental mutations to the probability tables during sampling.
Test 9: Chunked prefill == Full prefill
Chunked prefill splits a long prompt into smaller chunks and processes them sequentially, accumulating the KV cache across forward calls. The logits at the final position must match a single-shot full prefill.
# Full prefill
logits_full, _, kvs_full = model(prompt_t, pos=pos_full)
# Chunked prefill
kvs_chunked = None
for start in range(0, prompt_len, chunk_size):
end = min(start + chunk_size, prompt_len)
chunk = torch.tensor([prompt[start:end]], dtype=torch.long, device=device)
pos = torch.arange(start, end, device=device).unsqueeze(0)
logits_chunked, _, kvs_chunked = model(chunk, pos=pos, past_kvs=kvs_chunked)
The full prefill is straightforward: feed the entire prompt tensor and get logits + KV cache in one pass.
The chunked path iterates in steps of chunk_size (4 tokens). range(0, prompt_len, chunk_size) generates chunk starts: 0, 4, 8, 12. end = min(start + chunk_size, prompt_len) handles the last chunk which may be shorter than chunk_size (e.g., if prompt_len = 14, the last chunk is positions 12–13, only 2 tokens).
pos = torch.arange(start, end) gives each chunk token its correct absolute position. This is critical: position 8 is position 8 regardless of which chunk it arrives in. If positions were computed relative to the chunk (0, 1, 2, 3 every time), the model’s positional embeddings would be wrong and the test would fail.
past_kvs=kvs_chunked passes the accumulated cache from previous chunks. On the first chunk, kvs_chunked is None (no cache). On subsequent chunks, the model concatenates the new chunk’s KV entries onto the existing cache.
Three properties are verified:
- Logits match at the last position (
atol=1e-5). - KV cache shapes match - the chunked path must accumulate the same total cache length.
- First decode token matches - the argmax token from each prefill must be identical.
This catches bugs in positional-encoding threading across chunk boundaries, KV-cache concatenation order, and off-by-one errors in prefill_cursor logic.
Test 10: Fused interleaved == Sequential
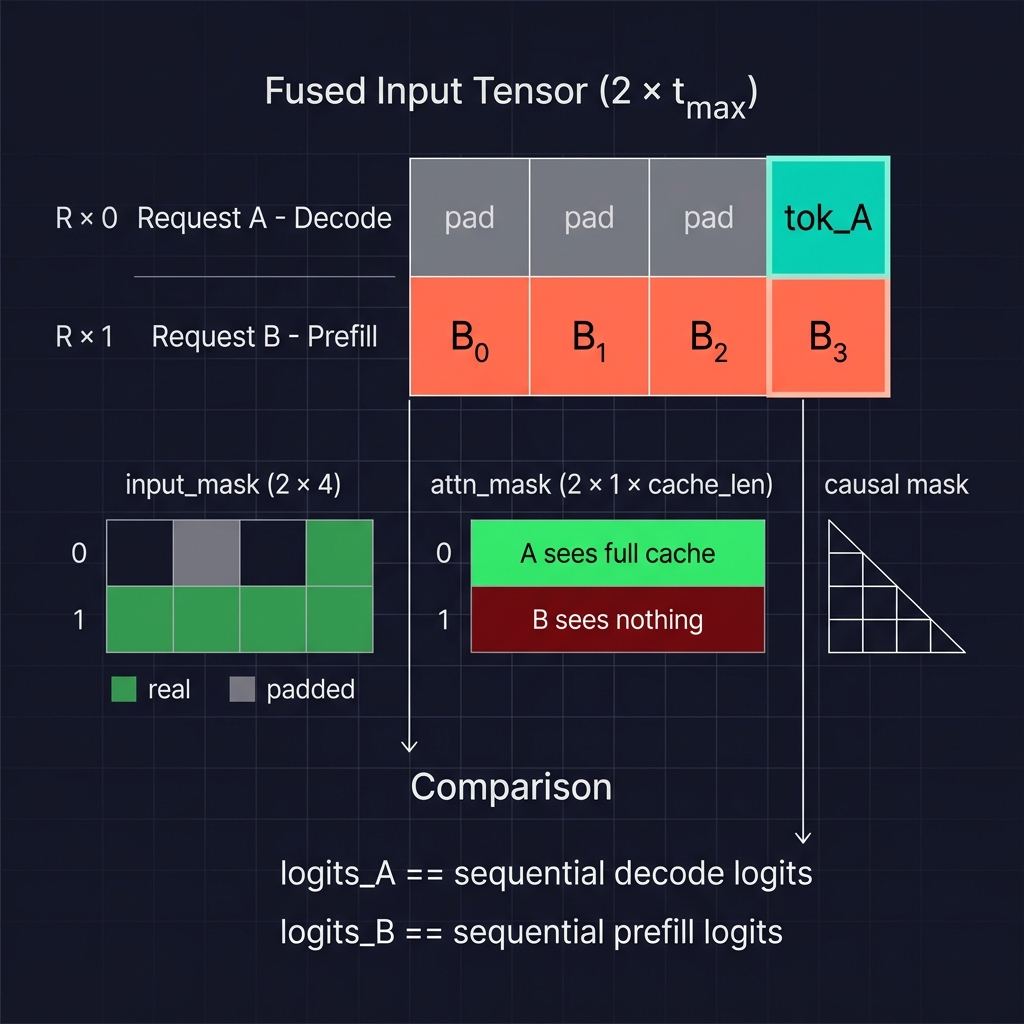
The most complex equivalence test. Interleaved scheduling packs a decode token and a prefill chunk into one batched forward pass, using left-padding and attention masks to prevent the two requests from interfering.
Setup:
- Request A has been prefilled and decoded one step. It has a populated KV cache and wants to decode its next token.
- Request B is a new arrival. It needs to prefill its first chunk.
Sequential: Run A’s decode and B’s prefill as separate forward calls.
Fused: Pack both into a single forward. Row 0 is A’s decode token (left-padded to match the prefill chunk length). Row 1 is B’s prefill chunk.
# Build input ids: pad decode row on the left with zeros
fused_ids = torch.zeros((2, t_max), dtype=torch.long, device=device)
fused_ids[0, -1] = second_a # decode token at last position
fused_ids[1, :chunk_size] = b_chunk # prefill chunk
t_max is the maximum sequence length across the two rows - equal to chunk_size since the prefill chunk is longer than the single decode token. fused_ids is initialized to zeros (pad tokens). Row 0 places the decode token at position -1 (the last column), left-padding the rest with zeros. Row 1 places the prefill chunk starting at position 0, filling chunk_size positions.
# Attention mask
attn_mask = torch.zeros((2, 1, cache_len_a), dtype=torch.bool, device=device)
attn_mask[0, :, :] = True # A can see its entire cache
# attn_mask[1] stays False - B has no cached positions
# Input mask
input_mask = torch.zeros((2, t_max), dtype=torch.bool, device=device)
input_mask[0, -1] = True # only last position is real for decode
input_mask[1, :chunk_size] = True # first chunk_size positions are real for prefill
Three masks control isolation between the two rows:
attn_mask has shape (2, 1, cache_len_a) - it controls which cached KV positions each row can attend to. Row 0 (A) sets all positions to True because A has a real cache it needs to attend to. Row 1 (B) stays False everywhere because B has no cached history - it is starting fresh.
input_mask has shape (2, t_max) - it marks which input positions contain real tokens vs. padding. Row 0 marks only the last position as real (the decode token). Row 1 marks the first chunk_size positions as real. This prevents the model from computing meaningful output at padded positions and, critically, prevents padded positions from corrupting the softmax in self-attention.
Both rows’ logits are compared against their sequential counterparts. A’s decode logits are at position t_max - 1 (the last column, where the real token lives). B’s prefill logits are at position chunk_size - 1 (the last real prefill position).
This test exercises:
- Left-padding correctness (padded positions must not influence real logits)
- Attention mask enforcement (B must not attend to A’s cached KV)
- Input mask enforcement (A’s padded input positions must not produce meaningful output)
- Position encoding under non-contiguous real positions
If any mask is wrong, one request’s logits leak into the other’s, and the comparison fails.
Running the suite
All ten tests are collected in a single runner:
def run_all_correctness_tests(model, *, vocab_size, device, block_size,
train_data, val_data):
results = {}
results["test1_recompute_vs_kv"] = test_recompute_vs_kv_cache(model, **kwargs)
results["test2_unbatched_vs_batched"] = test_unbatched_vs_batched(model, **kwargs)
results["test3_contiguous_vs_paged"] = test_contiguous_vs_paged_kv(model, **kwargs)
results["test4_prefix_cached"] = test_prefix_cached_vs_normal(model, **kwargs)
results["test5_spec_decode_greedy"] = test_speculative_greedy_vs_autoregressive(model, **kwargs)
results["test6_spec_distribution"] = test_spec_decode_distribution(model, **kwargs)
results["test7_kv_trim"] = test_kv_cache_trim(model, **kwargs)
results["test8_draft_distributions"] = test_draft_model_distributions(**kwargs)
results["test9_chunked_prefill"] = test_chunked_vs_full_prefill(model, **kwargs)
results["test10_fused_interleaved"] = test_fused_interleaved_vs_sequential(model, **kwargs)
Test 8 (draft model distributions) does not need the transformer model. All others require a trained model, training data, and validation data.
Each test reports ✅ PASS or ❌ FAIL. The runner prints a summary at the end.
What these tests do not cover
These tests verify equivalence - that the optimized path produces the same output as the baseline. They do not test:
- Output quality. A model that produces garbage will pass every test as long as it produces the same garbage through both paths.
- Performance. None of the tests measure throughput, latency, or memory. A correct but slow optimization would pass.
- Edge cases at scale. The tests run on a tiny model with short sequences. Cache eviction under memory pressure, very long contexts near
block_size, and high-concurrency batch scheduling are not exercised. - Numerical stability. The
atol=1e-5tolerance handles normal floating-point divergence. Catastrophic cancellation or accumulation errors at longer sequences would need tighter analysis.
Summary
| Test | Optimization | Method |
|---|---|---|
| 1 | KV cache | Cached logits == full-recompute logits |
| 2 | Continuous batching | Batched tokens == unbatched tokens |
| 3 | Paged attention | Paged KV tokens == contiguous KV tokens |
| 4 | Prefix caching | Cached-prefix tokens == full-prefill tokens |
| 5 | Speculative decoding (greedy) | Spec tokens == autoregressive tokens |
| 6 | Speculative decoding (sampling) | Spec histogram ≈ target histogram (χ²) |
| 7 | KV cache trim | Trimmed-cache logits == recomputed logits |
| 8 | Draft models | Distributions are normalized and peaked |
| 9 | Chunked prefill | Chunked logits == full-prefill logits |
| 10 | Interleaved scheduling | Fused-batch logits == sequential logits |
Every inference optimization in the engine has a test that proves it produces the same output as the simplest baseline. The tests use argmax decoding to eliminate sampling noise, except Test 6, which specifically verifies that the sampling distribution is preserved.
The broader principle: benchmarks measure how fast an optimization runs. Correctness tests measure whether it produces the right answer. Both are necessary. Only one is sufficient to ship a bug.
You can find the full test suite here: https://github.com/czhou578/multimodal-inference-visualizer/blob/main/benchmarks/test_correctness_equivalence.py
CZ