NanoGPT - Adding a Simple HTTP Server
Up until now, the NanoGPT inference engine has been a Python function that you call from the same process. You pass in a list of Request objects, call scheduled_generate(), and it runs the scheduler loop until all requests are done. That’s fine for benchmarking and correctness tests, but it’s not how anyone actually uses an LLM.
In production, inference servers expose an HTTP API. Clients send prompts, and the server streams tokens back as they’re generated. The client doesn’t wait for the full response - each token arrives over the wire as soon as it’s produced. These are Server-Sent Events (SSE), and it’s what makes ChatGPT’s typing animation work on the frontend console.
This post adds a streaming HTTP server to our NanoGPT inference engine. The server takes our existing scheduler, radix tree, chunked prefill, and continuous batching code and wraps it in a FastAPI application that accepts concurrent requests over HTTP and streams tokens back in real-time.
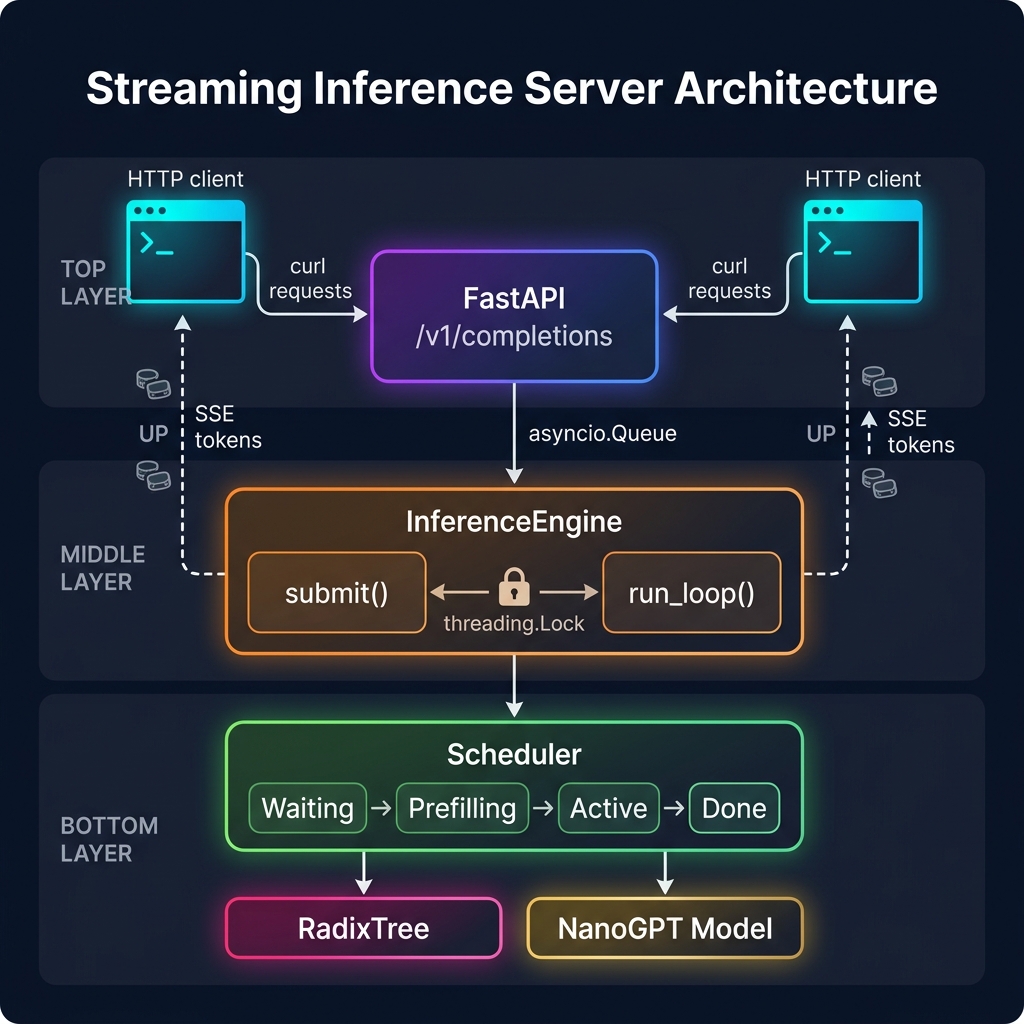
The interesting part is the threading boundary between the async HTTP layer and the synchronous inference loop, and how we pipe tokens from PyTorch back to curl.
The problem: two incompatible execution models
Our inference engine runs a tight synchronous loop: call scheduler.schedule(), run a model forward pass, sample tokens, update KV caches, repeat. This loop must be synchronous because PyTorch operations are blocking - model(input_ids, pos=pos, past_kvs=past_kvs) doesn’t return until the GPU (or CPU) finishes the computation.
But HTTP servers need to be asynchronous. When a client sends a request, the server can’t block the entire process waiting for 50 tokens to be generated - other clients would be locked out. FastAPI uses asyncio for this: each request gets a coroutine that can yield control while waiting for data.
You can’t await a PyTorch forward pass, and you can’t run asyncio inside a blocking inference loop. The solution is to put them in separate threads and connect them with thread-safe queues.
Loading the engine
First, the server needs to load the model and all the inference machinery (Scheduler, RadixTree, etc.).
def _load_engine_module():
"""Import nanogpt-radix-tree-.py despite its non-standard filename."""
path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "nanogpt-radix-tree-.py")
spec = importlib.util.spec_from_file_location("_nanogpt_engine", path)
mod = importlib.util.module_from_spec(spec)
spec.loader.exec_module(mod)
return mod
E = _load_engine_module() # short alias - all engine symbols live here
The engine file has a non-standard filename (nanogpt-radix-tree-.py - the dash makes it un-importable with a normal import statement). So we use importlib.util to load it manually. spec_from_file_location creates a module spec from the file path, module_from_spec creates an empty module object, and exec_module runs the file’s code to populate it. The result is a module E that contains all our engine classes - E.GPTLanguageModel, E.Scheduler, E.Request, E.RadixTree, E.encode, E.decode, etc.
The if __name__ == "__main__" guard in the engine file prevents the training loop and benchmarks from running when we import it - only the class definitions and function definitions are executed.
Training at startup
def _train_model():
print(f"Training NanoGPT on {E.device}...")
model = E.GPTLanguageModel().to(E.device)
print(f" {sum(p.numel() for p in model.parameters()) / 1e6:.3f}M parameters")
optimizer = torch.optim.AdamW(model.parameters(), lr=E.learning_rate)
for i in range(E.max_iters):
xb, yb = E.get_batch("train")
logits, loss, _ = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
if i % E.eval_interval == 0 or i == E.max_iters - 1:
print(f" step {i}: loss {loss.item():.4f}")
model.eval()
print("Model trained and ready.\n")
return model
MODEL = _train_model()
The model trains when the server process starts. This is a deliberate simplification - a production server would load pretrained weights from a checkpoint. But since our model is tiny (57K parameters, 120 training iterations on Tiny Shakespeare), training takes a few seconds and saves us from managing checkpoint files.
model.eval() at the end switches the model from training mode to inference mode. This disables dropout and sets batch norm to use running statistics. The MODEL variable is module-level - it’s created once and shared by all requests for the lifetime of the server process.
The InferenceEngine class
This is the heart of the server. It wraps the existing Scheduler and runs the inference loop in a background thread, while exposing a submit() method that HTTP handlers can call from the async main thread.
class InferenceEngine:
def __init__(self, model, max_batch_size=8, token_budget=64,
max_kv_tokens=512, block_size=4):
self.model = model
self.scheduler = E.Scheduler(
policy="fcfs",
max_batch_size=max_batch_size,
token_budget=token_budget,
max_kv_tokens=max_kv_tokens,
block_size=block_size,
)
self.step = 0
# Pending requests (written by HTTP handlers, read by engine thread)
self._pending: list = []
self._lock = threading.Lock()
# Per-request token delivery queues
self._queues: dict[int, asyncio.Queue] = {}
self._submit_times: dict[int, float] = {}
self._next_id = 0
# Set by startup so the engine thread can push to asyncio queues
self._loop: asyncio.AbstractEventLoop | None = None
There’s a lot going on in this __init__, so let me walk through the design decisions:
self.scheduler is a regular Scheduler instance; the same one we used in the benchmark scripts. It manages the waiting, prefilling, and active queues, and owns the radix tree for prefix caching. Nothing about the scheduler changes for the server - it’s still a synchronous, single-threaded component.
self._pending is the inbox. HTTP handlers write new requests here, and the engine thread reads from it. This is the crossing point between the two threads, which is why it has a threading.Lock guarding it. We use a plain list instead of queue.Queue because we want to drain all pending requests at once at the top of each engine loop iteration (batch drain), not pull them one at a time.
self._queues maps request_id → asyncio.Queue. When the engine generates a token for request 7, it pushes the token into self._queues[7]. On the other side, the HTTP handler for request 7 is await-ing on the same queue. This is how tokens flow from the engine thread back to the client.
self._loop stores a reference to the asyncio event loop. The engine thread needs this to push items into asyncio queues from a non-async context. We’ll see why in a moment.
Submitting requests
def submit(self, prompt_tokens: list[int], max_tokens: int) -> tuple[int, asyncio.Queue]:
"""Create a request and return (request_id, token_queue)."""
req_id = self._next_id
self._next_id += 1
req = E.Request(
id=req_id,
prompt_tokens=prompt_tokens,
max_new_tokens=max_tokens,
)
req.arrival_time = self.step
queue = asyncio.Queue()
with self._lock:
self._pending.append(req)
self._queues[req_id] = queue
self._submit_times[req_id] = time.perf_counter()
return req_id, queue
submit() is called from the FastAPI handler (main thread). It creates an E.Request object - the exact same dataclass the benchmark harness uses - and drops it into self._pending under the lock. It also creates an asyncio.Queue for this request and stores the submit time (for TTFT measurement later).
The caller gets back (req_id, queue). The queue is the channel for receiving tokens - the HTTP handler will await queue.get() in a loop, yielding each token to the client as an SSE event.
The thread boundary
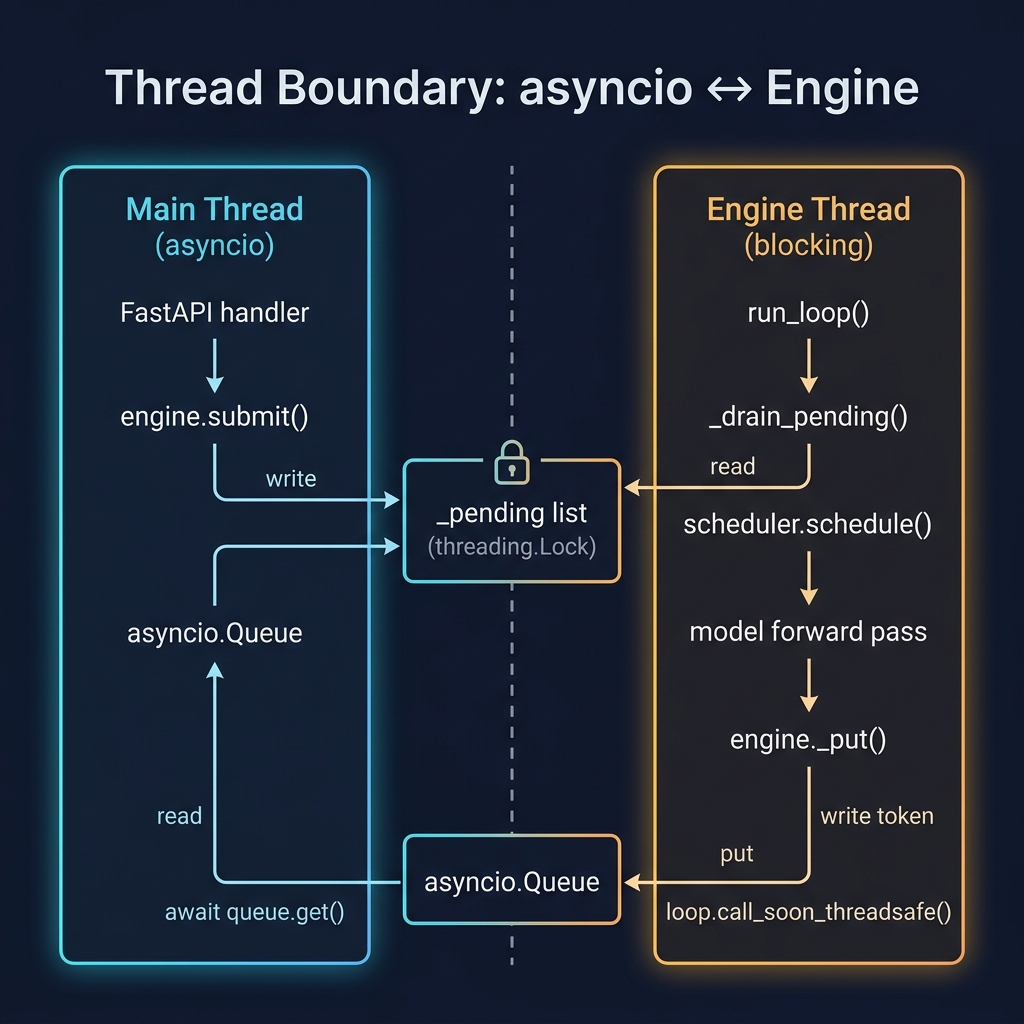
This is the trickiest part of the whole server. The engine thread generates tokens with blocking PyTorch calls. The HTTP handler needs to receive them asynchronously. These are in different threads with different execution models.
Three helper methods handle the boundary:
def _drain_pending(self):
with self._lock:
batch = list(self._pending)
self._pending.clear()
for req in batch:
self.scheduler.add_request(req)
_drain_pending() is called at the top of every engine loop iteration. It grabs all pending requests under the lock, clears the list, and adds them to the scheduler. The lock is held for the minimum possible time - just long enough to copy the list and clear it. This avoids contention: HTTP handlers can keep submitting requests while the engine processes the current batch.
def _put(self, req_id: int, item):
"""Thread-safe push into an asyncio.Queue."""
q = self._queues.get(req_id)
if q and self._loop:
self._loop.call_soon_threadsafe(q.put_nowait, item)
This is the key method. _put() pushes a token into the asyncio queue from the engine thread. You can’t just call q.put_nowait(item) directly - asyncio.Queue is not thread-safe. Instead, we use self._loop.call_soon_threadsafe(), which schedules the put_nowait call on the asyncio event loop’s thread. This is the standard pattern for pushing data from a background thread into asyncio.
def _finish(self, req_id: int):
self._put(req_id, None) # sentinel
self._queues.pop(req_id, None)
self._submit_times.pop(req_id, None)
When a request is done, _finish() pushes a None sentinel into the queue (signaling “no more tokens”) and cleans up the queue and timing entries. The HTTP handler’s loop will see the None and close the SSE stream.
The engine loop
def run_loop(self):
"""Main engine loop - mirrors scheduled_generate but never terminates."""
self.model.eval()
with torch.no_grad():
while True:
self._drain_pending()
has_work = (
self.scheduler.waiting
or self.scheduler.prefilling
or self.scheduler.active
)
if not has_work:
time.sleep(0.01)
continue
prefill_req, decode_reqs = self.scheduler.schedule(self.step)
This is structurally identical to scheduled_generate() from the benchmark harness, with one critical difference: it never terminates. Instead of while not scheduler.is_done(), it runs while True and sleeps for 10ms when idle. This keeps the engine thread alive, ready to pick up new requests as they arrive via HTTP.
The time.sleep(0.01) is important. Without it, an idle engine would spin at 100% CPU checking empty queues. 10ms of sleep is long enough to avoid wasting CPU but short enough that new requests start processing with negligible delay.
Prefill with token streaming
if prefill_req:
remaining_budget = self.scheduler.token_budget - len(self.scheduler.active)
if remaining_budget > 0 and self.scheduler.prefilling:
p_req = self.scheduler.prefilling[0]
tokens_left = len(p_req.prompt_tokens) - p_req.prefill_cursor
chunk_size = min(remaining_budget, tokens_left)
chunk_start = p_req.prefill_cursor
chunk_tokens = p_req.prompt_tokens[chunk_start:chunk_start + chunk_size]
prefill_chunk = torch.tensor(
[chunk_tokens], dtype=torch.long, device=E.device
)
p_req.prefill_cursor += chunk_size
pos = torch.arange(
chunk_start, chunk_start + chunk_size, device=E.device
).unsqueeze(0)
if p_req.kv_cache:
past_kvs = []
for li in range(E.n_layer):
past_kvs.append(
[p_req.kv_cache[(li, hi)] for hi in range(E.n_head)]
)
logits, _, new_kvs = self.model(
prefill_chunk, pos=pos, past_kvs=past_kvs
)
else:
logits, _, new_kvs = self.model(prefill_chunk, pos=pos)
for li, bkv in enumerate(new_kvs):
for hi, (k, v) in enumerate(bkv):
p_req.kv_cache[(li, hi)] = (k, v)
The prefill logic is identical to the benchmark harness. Chunked prefill processes chunk_size tokens per iteration, respecting the token budget. If the request has cached KV from the radix tree (loaded during admission), we pass it as past_kvs. Positions use absolute indices (chunk_start to chunk_start + chunk_size) so the positional embeddings are correct regardless of which chunk we’re processing.
The new part is what happens when prefill completes:
if prefill_req.is_fully_prefilled:
E.insert_into_radix_tree(
prefill_req,
self.scheduler.radix_tree,
self.scheduler.block_size,
)
token_id = idx_next.item()
prefill_req.generated_tokens.append(token_id)
prefill_req._last_token = idx_next
self.scheduler.radix_tree.unlock_radix_path(prefill_req)
self.scheduler.promote(prefill_req)
# Stream the first token
self._put(prefill_req.id, {
"token": E.decode([token_id]),
"token_id": token_id,
"is_first": True,
"ttft_ms": round(
(time.perf_counter() - self._submit_times.get(prefill_req.id, 0)) * 1000, 1
),
})
After prefill finishes and the first token is sampled, we insert the prompt’s KV data into the radix tree (so future requests with the same prefix can skip prefill), unlock the tree path, promote the request to the active decode queue, and - this is the new part - stream the first token back to the client.
The self._put() call pushes a dict with the decoded token string, the raw token ID, an is_first flag, and the TTFT measurement (time from submit() to this moment, in milliseconds). The client sees this as the first SSE event in the stream.
Decode with per-token streaming
if decode_reqs:
active = self.scheduler.active
batch_tokens = torch.cat([r._last_token for r in active])
batch_positions = torch.tensor(
[[len(r.tokens_so_far) - 1] for r in active],
device=E.device,
)
past_kvs, attn_mask, pad_lengths = E.assemble_batch_cache(active)
logits, _, new_kvs = self.model(
batch_tokens,
pos=batch_positions,
past_kvs=past_kvs,
attn_mask=attn_mask,
)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
E.disassemble_batch_cache(active, new_kvs, pad_lengths)
for i, req in enumerate(active):
token_id = idx_next[i].item()
req.generated_tokens.append(token_id)
req._last_token = idx_next[i:i + 1]
# Stream the token
self._put(req.id, {
"token": E.decode([token_id]),
"token_id": token_id,
"is_first": False,
})
for req in list(active):
if req.is_done:
self.scheduler.radix_tree.unlock_radix_path(req)
self.scheduler.complete(req)
self._finish(req.id)
The decode step batches all active requests together using assemble_batch_cache (left-padding shorter caches so the batch is rectangular), runs one forward pass, and scatters the results back with disassemble_batch_cache. This is the same continuous batching we built in the earlier posts.
The new addition: after each token is sampled, it’s immediately pushed to the corresponding client’s queue via self._put(). The client doesn’t wait for all 50 tokens - each one arrives as soon as it’s computed. This is what makes the streaming feel real-time.
When a request hits its max_new_tokens limit, self._finish() sends the None sentinel and cleans up. The client’s SSE stream closes cleanly.
The FastAPI layer
app = FastAPI(title="NanoGPT Streaming Server")
engine = InferenceEngine(MODEL)
class CompletionRequest(BaseModel):
prompt: str
max_tokens: int = 50
The engine instance is created at module level - one engine per server process. CompletionRequest is a Pydantic model that validates incoming JSON. If a client sends {"prompt": "First Citizen:", "max_tokens": 50}, Pydantic parses it into a typed object. If max_tokens is omitted, it defaults to 50.
Startup: wiring the threads together
@app.on_event("startup")
async def startup():
engine._loop = asyncio.get_event_loop()
thread = threading.Thread(target=engine.run_loop, daemon=True)
thread.start()
print("Engine loop started.")
startup() runs once when the FastAPI application starts. It does two things: saves a reference to the asyncio event loop (so the engine thread can use call_soon_threadsafe), and launches the engine loop in a daemon thread. daemon=True means the thread dies when the main process exits - no cleanup needed.
This is the moment the two threads begin their independent lives. The main thread runs the asyncio event loop (handling HTTP requests), and the engine thread runs the inference loop (doing PyTorch forward passes).
The streaming endpoint
@app.post("/v1/completions")
async def completions(req: CompletionRequest):
prompt_tokens = E.encode(req.prompt)
req_id, queue = engine.submit(prompt_tokens, req.max_tokens)
async def stream():
full_text = ""
while True:
item = await queue.get()
if item is None:
yield f"data: {json.dumps({'done': True, 'full_text': full_text})}\n\n"
break
full_text += item["token"]
yield f"data: {json.dumps(item)}\n\n"
return StreamingResponse(stream(), media_type="text/event-stream")
This is the HTTP endpoint. When a client POSTs to /v1/completions, the handler encodes the prompt, submits it to the engine, and returns a StreamingResponse backed by an async generator.
The stream() generator loops forever, awaiting on the queue. Each time the engine pushes a token, queue.get() unblocks and the generator yields an SSE line (data: {...}\n\n). When the engine sends None, the generator yields a final done event with the full accumulated text and breaks.
StreamingResponse with media_type="text/event-stream" tells FastAPI to keep the HTTP connection open and flush each yield to the client immediately. This is standard SSE - the client sees tokens appearing one by one as they’re generated.
Health check
@app.get("/health")
def health():
return {
"step": engine.step,
"waiting": len(engine.scheduler.waiting),
"prefilling": len(engine.scheduler.prefilling),
"active": len(engine.scheduler.active),
"pending_submit": len(engine._pending),
}
A simple diagnostic endpoint. curl localhost:8000/health returns the current engine state - how many requests are in each queue, what step the engine is on, and how many requests are waiting to be drained from the pending list. Useful for debugging concurrency issues.
Using it
Start the server:
python server.py
The model trains for ~120 iterations, then the server starts on port 8000. Send a request:
curl -N http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{"prompt": "First Citizen:", "max_tokens": 50}'
The -N flag disables curl’s output buffering, so you see tokens streaming in real-time. Each line is an SSE event:
data: {"token": " W", "token_id": 36, "is_first": true, "ttft_ms": 12.3}
data: {"token": "e", "token_id": 43, "is_first": false}
data: {"token": " ", "token_id": 1, "is_first": false}
...
data: {"done": true, "full_text": " We are accounted poor citizens..."}
Send two requests in parallel (separate terminals) and they’ll be continuously batched:
curl -N ... -d '{"prompt": "ROMEO:", "max_tokens": 30}'
curl -N ... -d '{"prompt": "JULIET:", "max_tokens": 30}'
Both streams will interleave tokens. The scheduler handles them as a batch, same as the benchmark harness.
Send the same prefix twice to trigger a radix cache hit:
curl -N ... -d '{"prompt": "First Citizen: We are accounted poor", "max_tokens": 20}'
# (wait a moment, then:)
curl -N ... -d '{"prompt": "First Citizen: We are accounted poor", "max_tokens": 20}'
The second request skips prefill for the shared prefix - the KV cache is loaded from the radix tree. You’ll see a lower TTFT on the second request.
What this doesn’t do
This server is intentionally minimal. A production inference server (vLLM, SGLang, TensorRT-LLM) would additionally have:
- Tokenization offloading. We tokenize in the HTTP handler, blocking the event loop. Production servers do this in a separate process.
- Backpressure. If the engine is overloaded, new requests should be rejected or queued with admission control. We just accept everything.
- Proper error handling. If the model forward pass throws, the client’s stream silently hangs. Production servers send error events.
- Multi-GPU. We run on a single device. Production servers shard the model across GPUs with tensor parallelism.
- OpenAI-compatible API. Our endpoint is a simplified version. The real OpenAI API has
stream: true,stopsequences,temperature,top_p, and many more parameters. - Graceful shutdown. We don’t drain active requests on SIGTERM. The daemon thread just dies.
But the core architecture - background engine thread, asyncio queue bridge, SSE streaming - is the same pattern that production servers use. The complexity is in the optimizations, not the skeleton.
You can find the full source code here: https://github.com/czhou578/multimodal-inference-visualizer/blob/main/server.py
CZ