Comparing NanoGPT vs vLLM
Over the past several posts we’ve built a surprisingly complete inference engine on top of Andrej Karpathy’s nanoGPT: paged attention, chunked prefill, continuous batching, prefix caching with a radix tree, and a streaming HTTP server. It works. You can curl it and watch Shakespeare stream back token-by-token.
But every time I opened vLLM’s source code to compare, I kept having the same reaction: oh, so that’s why they did it that way. Our NanoGPT engine captures the right ideas, but vLLM’s implementation reveals why the “obvious” approach to each idea doesn’t scale. The gap isn’t in the algorithms - it’s in the data structures, the ownership models, and the process boundaries.
This post is a walk through the differences I found most illuminating. I’m not trying to be exhaustive (vLLM’s block management subsystem alone is 80K+ lines). Instead, I want to focus on the places where the same concept maps to fundamentally different code, and why.
The high-level picture
Let me start with the two stacks side-by-side, because the shape alone tells you a lot:
vLLM’s Block Management Stack
┌─────────────────────────────────────────────┐
│ KVCacheManager (kv_cache_manager.py) │ ← Top-level API
│ Coordinates across cache groups │
├─────────────────────────────────────────────┤
│ SingleTypeKVCacheManager │ ← Per-group block management
│ (single_type_kv_cache_manager.py) │ Logical → physical mapping
├─────────────────────────────────────────────┤
│ BlockPool (block_pool.py) │ ← Physical block allocation
│ Free list, eviction, ref counting │
├─────────────────────────────────────────────┤
│ FreeKVCacheBlockQueue (kv_cache_utils.py) │ ← Doubly-linked free list
│ O(1) alloc, free, and mid-list removal │
├─────────────────────────────────────────────┤
│ KVCacheBlock (kv_cache_utils.py) │ ← Block metadata
│ block_id, ref_cnt, block_hash, linked │
│ list pointers │
└─────────────────────────────────────────────┘
NanoGPT’s Block Management Stack
┌─────────────────────────────────────────────┐
│ Scheduler (nanogpt-paged-attention.py) │ ← Top-level API
│ Admission, scheduling, preemption │
├─────────────────────────────────────────────┤
│ BlockAllocator │ ← Physical block allocation
│ Simple free list (Python list) │
├─────────────────────────────────────────────┤
│ KVBlockPool │ ← Physical GPU memory pool
│ Pre-allocated tensors per (layer, head) │
├─────────────────────────────────────────────┤
│ BlockCache │ ← Prefix caching
│ Hash → CachedBlock, LRU eviction │
└─────────────────────────────────────────────┘
vLLM has five layers. NanoGPT has four. But the real difference isn’t the layer count - it’s what lives on the block object itself. That single design decision ripples through everything else.
Where the block lives matters more than you’d think
Here is vLLM’s block:
@dataclass(slots=True)
class KVCacheBlock:
block_id: int
ref_cnt: int = 0
_block_hash: BlockHashWithGroupId | None = None
# Doubly-linked list pointers for O(1) free queue operations
prev_free_block: "KVCacheBlock | None" = None
next_free_block: "KVCacheBlock | None" = None
is_null: bool = False
And here is ours:
@dataclass
class CachedBlock:
block_hash: bytes
token_ids: tuple
kv_data: Dict[Tuple[int, int], Tuple[torch.Tensor, torch.Tensor]]
last_access_step: int = 0
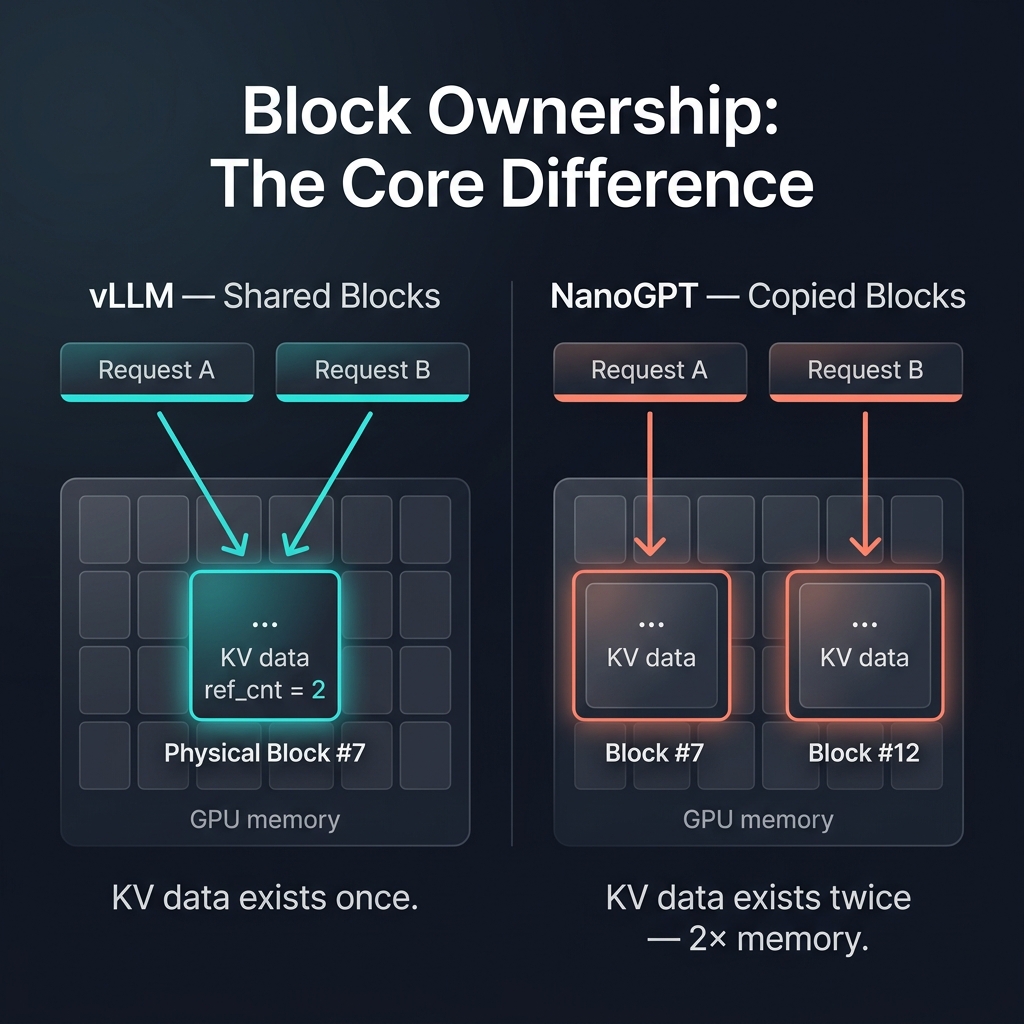
Notice what’s missing from vLLM’s block: there’s no KV data on it. The KVCacheBlock is pure metadata - maybe 64 bytes. The actual key-value tensors live in pre-allocated GPU memory, and block_id is just an index into that memory. The Python scheduler never touches the tensors at all.
Our CachedBlock stores KV tensor references directly on the object (kv_data). This is the simpler design - you look at a block and you can see its data right there. But it creates a problem that isn’t obvious until you try to share blocks between requests.
| Feature | vLLM | NanoGPT |
|---|---|---|
| Reference counting | ref_cnt field, incremented/decremented by touch() / free_blocks() |
Not implemented - blocks are simply in cache or not |
| Free list pointers | prev_free_block / next_free_block - intrusive doubly-linked list |
No linked list - free blocks are a Python list |
| Block hash | Stored as BlockHashWithGroupId (bytes), set only when block is full |
block_hash is bytes from MD5, set at insertion time |
| KV data location | Block ID is an index into pre-allocated GPU tensors (no KV on block object) | kv_data dict stored directly on the block object |
| Null block | is_null flag for placeholder blocks |
Not implemented |
| Memory layout | @dataclass(slots=True) for memory efficiency |
Standard @dataclass |
Here’s the consequence. In vLLM, when two requests share the same prefix, they can both point to the same physical block - ref_cnt goes to 2, and the KV data exists once in GPU memory. In NanoGPT, our load_cached_blocks_to_pool() copies the cached KV data into the request’s own physical blocks. Two requests with the same prefix use 2× the memory. That’s the cost of putting data on the block object: you can’t share ownership without sharing the object, and sharing the object means managing concurrent access, and pretty soon you’ve reinvented reference counting anyway.
The free list is a linked list for a reason
This was the one that surprised me the most. vLLM’s FreeKVCacheBlockQueue is a hand-rolled doubly-linked list with fake head and tail sentinels. In 2026. In Python.
Why not just use a Python list? That’s what we do - BlockAllocator is literally just self.free_blocks = list(range(num_blocks)) with pop() and extend(). It works fine.
The answer is touch(). When a cached block gets a cache hit, it needs to be yanked out of the free queue immediately - it’s being used again, so it shouldn’t be eligible for eviction anymore. With a Python list, list.remove(block) is O(n). With a deque, arbitrary removal isn’t even supported. But with an intrusive doubly-linked list (where the prev/next pointers live on the block object itself), removal is O(1): just rewire the neighbors. Zero scanning, zero allocation.
def touch(self, blocks):
for block in blocks:
if block.ref_cnt == 0 and not block.is_null:
self.free_block_queue.remove(block) # O(1) mid-list removal
block.ref_cnt += 1
NanoGPT doesn’t need this because we keep cached blocks and free blocks in completely separate data structures (BlockCache.cache dict vs BlockAllocator.free_blocks list). We never need to yank a block from the free list on a cache hit because cached blocks were never in the free list to begin with. Simpler, but less memory-efficient - we can’t reclaim cached blocks under memory pressure without a separate eviction path.
Hashing: same algorithm, different timing
The prefix cache in both systems relies on chained block hashing: you hash (parent_hash, token_ids) to get a unique identifier for each block’s position in a token sequence. If two different prompts share the first 16 tokens, their first block (assuming block_size=16) will produce the same hash, and you get a cache hit.
The hashing code is almost identical:
# vLLM
def hash_block_tokens(hash_function, parent_block_hash, curr_block_token_ids, extra_keys=None):
if not parent_block_hash:
parent_block_hash = NONE_HASH
return BlockHash(hash_function((parent_block_hash, tuple(curr_block_token_ids), extra_keys)))
# NanoGPT
def hash_block_tokens(parent_hash, token_ids):
data = (parent_hash, tuple(token_ids))
return hashlib.md5(str(data).encode()).digest()
Same idea. vLLM adds support for LoRA adapters, multimodal inputs, and cache salts (for security isolation), but the core is hash(parent, tokens).
The interesting difference is when the hashing happens. vLLM computes block hashes eagerly - the moment tokens are appended to a request, the hasher runs and stores the result on the Request object. Those hashes are then reused for both cache lookup and cache insertion. We recompute the entire hash chain from block 0 every time find_cached_prefix() is called. For a 1,000-token prompt with block_size=16, that’s 62 hash computations that could have been done once and cached. For our tiny Shakespeare model it doesn’t matter, but at production scale it would.
| Feature | vLLM | NanoGPT |
|---|---|---|
| Hash function | Configurable (sha256_cbor, xxhash_cbor, or custom) |
Hardcoded hashlib.md5 |
| Parent chaining | parent_block_hash parameter, NONE_HASH sentinel |
Same pattern, NONE_HASH = b'\x00' * 16 |
| Extra keys | Supports LoRA, multimodal, cache salt, prompt embeds | Not supported |
| Block hash type | NewType("BlockHash", bytes) - type-safe |
Raw bytes |
The cache lookup tells you a lot
Comparing how the two systems look up cached prefixes reveals how all the earlier design decisions compound:
# vLLM - single hash lookup per block (hashes pre-computed on Request)
def get_cached_block(self, block_hash, kv_cache_group_ids):
cached_blocks = []
for group_id in kv_cache_group_ids:
block_hash_with_group_id = make_block_hash_with_group_id(block_hash, group_id)
block = self.cached_block_hash_to_block.get_one_block(block_hash_with_group_id)
if not block:
return None
cached_blocks.append(block)
return cached_blocks
# NanoGPT - recomputes hash chain per lookup
def find_cached_prefix(block_cache, prompt_tokens, block_size):
num_cached = 0
parent_hash = NONE_HASH
for start in range(0, len(prompt_tokens), block_size):
end = start + block_size
if end > len(prompt_tokens): break
chunk = prompt_tokens[start:end]
chunk_hash = hash_block_tokens(parent_hash, chunk)
cached_block = block_cache.lookup(chunk_hash)
if cached_block is None: break
num_cached += block_size
parent_hash = chunk_hash
return num_cached
vLLM’s version is almost trivial - it’s just a dict lookup, because the hash was already computed when the request arrived. Ours does the hashing inline and walks the chain block-by-block. Same result, but you can see how the eager-hashing decision from earlier pays off here.
Eviction: same policy, wildly different performance
Both systems use LRU eviction. But “LRU” is a policy, not an implementation, and the implementations couldn’t be more different.
vLLM’s eviction is implicit in the free queue ordering. Blocks go to the back of the free list when freed. When you need a new block, you take from the front. So the front always has the oldest (least recently used) blocks. Eviction is O(1) - you just pop from the front and, if it was a cached block, clear its hash.
Our eviction is a linear scan:
def _evict_lru(self):
oldest = min(self.cache.values(), key=lambda b: b.last_access_step)
del self.cache[oldest.block_hash]
That’s O(n) in the number of cached blocks. For our 128-block pool it takes microseconds. For vLLM’s 100K+ block pools it would be catastrophic.
| Feature | vLLM | NanoGPT |
|---|---|---|
| Ref counting | Explicit ref_cnt - block is free only when count reaches 0 |
Not implemented - blocks are either cached or free |
| Eviction trigger | When allocating from free queue, cached blocks at front are evicted | When cache exceeds max_blocks, LRU block is evicted |
| Eviction selection | Implicit LRU via queue ordering - front of free list evicted first | Explicit min() scan over all cached blocks - O(n) |
| Shared blocks | Multiple requests can reference the same block (ref_cnt > 1) |
Not supported - each request has its own block table |
Writing KV data: Python loops vs CUDA kernels
This is the section where the performance gap goes from “noticeable” to “comical.” In vLLM, KV data is written to physical blocks by custom CUDA kernels - reshape_and_cache_flash in csrc/ - that directly index into pre-allocated GPU tensors using the block table. The Python scheduler never touches KV tensor data. It doesn’t even see the tensors.
In NanoGPT, we do this:
def write_kv_to_pool(pool, block_table, block_size, start_pos, k_new, v_new, layer, head):
T_new = k_new.shape[1]
for t in range(T_new):
logical_pos = start_pos + t
block_idx = logical_pos // block_size
slot_idx = logical_pos % block_size
phys_block = block_table[block_idx]
pool.k_pool[(layer, head)][phys_block, slot_idx, :] = k_new[0, t, :]
pool.v_pool[(layer, head)][phys_block, slot_idx, :] = v_new[0, t, :]
A Python for-loop, writing one slot at a time, with dictionary lookups on every iteration. Same logical operation - “put this KV vector into that physical slot” - but vLLM does it in fused CUDA while we do it in Python. This is fine for education, but it’s also a good reminder of what “systems optimization” actually means at the kernel level: it’s not a different algorithm, it’s the same algorithm in a different language with different memory access patterns.
| Feature | vLLM | NanoGPT |
|---|---|---|
| KV write | CUDA kernel (reshape_and_cache_flash) |
Python loop with tensor indexing |
| Indexing | Physical block table passed to kernel | block_table[logical // block_size] |
| Performance | GPU-accelerated, fused with attention | CPU-bound Python loop (educational) |
| Batch support | Handles entire batch in one kernel call | One request at a time |
The scheduler: where the design philosophies diverge
Up to this point, the differences have been mostly about performance and data structure choices. The scheduler is where the systems diverge conceptually.
There is no “prefilling” in vLLM
This was the biggest surprise. NanoGPT has an explicit state machine:
status: str = "waiting" # "waiting" -> "prefilling" -> "active" -> "done"
vLLM has twelve states, but none of them are “prefilling”:
class RequestStatus(enum.IntEnum):
WAITING = auto()
WAITING_FOR_STRUCTURED_OUTPUT_GRAMMAR = auto()
WAITING_FOR_REMOTE_KVS = auto()
WAITING_FOR_STREAMING_REQ = auto()
RUNNING = auto()
PREEMPTED = auto()
FINISHED_STOPPED = auto()
FINISHED_LENGTH_CAPPED = auto()
FINISHED_ABORTED = auto()
FINISHED_IGNORED = auto()
FINISHED_ERROR = auto()
FINISHED_REPETITION = auto()
Instead, every request just has a num_computed_tokens counter. If num_computed_tokens < num_tokens, the request still has prefill work to do. If num_computed_tokens == num_tokens, it’s decoding. The scheduler doesn’t care - it just assigns however many new tokens fit in the budget.
This is a genuinely elegant unification. It means chunked prefill falls out naturally (a request gets partial tokens across multiple steps), resumed requests after preemption work the same way (just reset num_computed_tokens to 0), and speculative decoding slots in too (extra tokens need computing). Our explicit "prefilling" → "active" transition is easier to read, but it’s a less flexible abstraction.
Running requests always go first
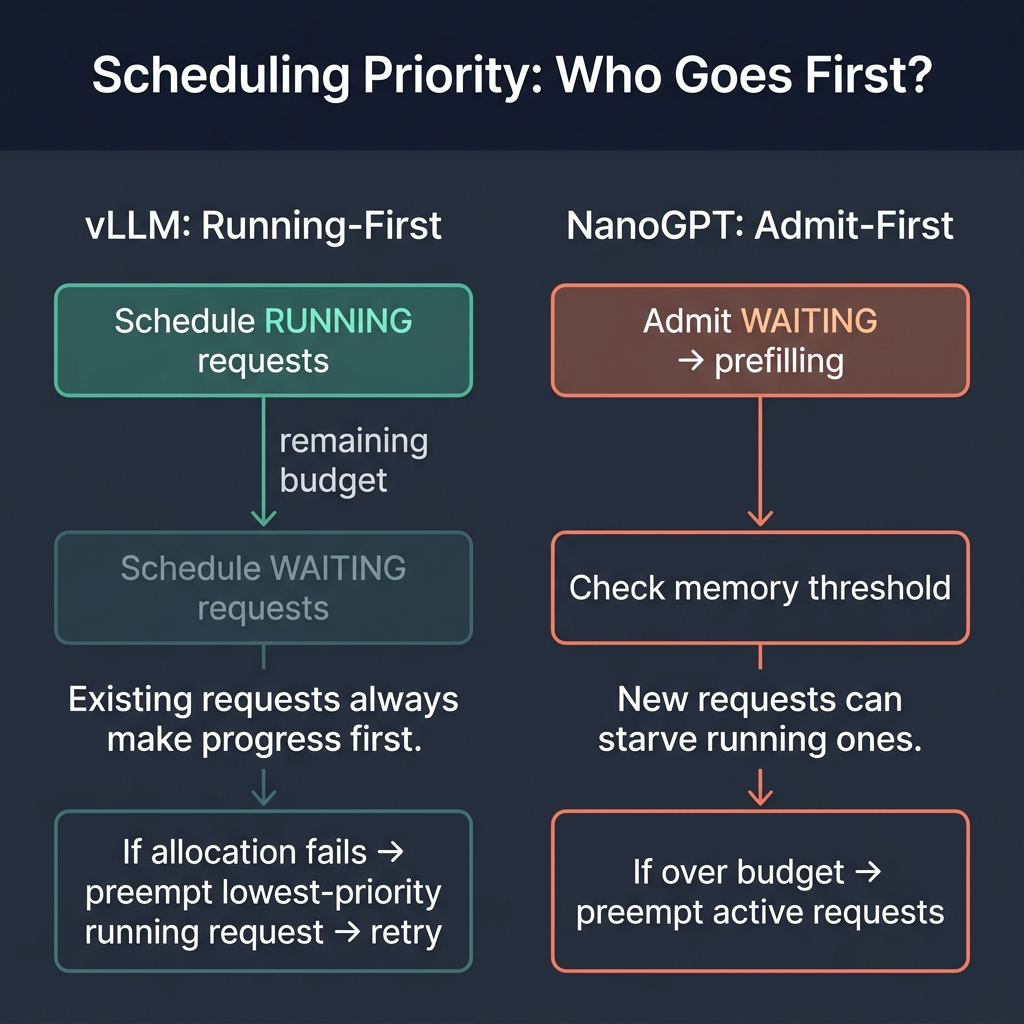
Here’s another difference that looks minor but has real consequences. vLLM’s scheduling loop has two phases:
def schedule(self) -> SchedulerOutput:
# Phase 1: Schedule RUNNING requests first
while req_index < len(self.running) and token_budget > 0:
num_new_tokens = request.num_tokens_with_spec - request.num_computed_tokens
num_new_tokens = min(num_new_tokens, token_budget)
new_blocks = self.kv_cache_manager.allocate_slots(request, num_new_tokens)
if new_blocks is None:
self._preempt_request(preempted_req)
...
# Phase 2: Schedule WAITING requests with remaining budget
while self.waiting and token_budget > 0:
num_computed_tokens = self.kv_cache_manager.get_computed_blocks(request)
num_new_tokens = request.num_tokens - num_computed_tokens
num_new_tokens = min(num_new_tokens, token_budget)
new_blocks = self.kv_cache_manager.allocate_slots(request, num_new_tokens)
...
Running requests go first. Only after every running request has its tokens does the scheduler look at waiting requests with whatever budget remains. This is critical for preventing starvation - you don’t want a flood of new requests to steal tokens from requests that are mid-generation.
NanoGPT does the opposite:
def schedule(self, step: int):
self._maybe_admit(step) # promote waiting → prefilling if memory allows
self._maybe_preempt() # evict if over memory budget
prefill_req = self.prefilling[0] if self.prefilling else None
decode_reqs = list(self.active)
return prefill_req, decode_reqs
We admit first, then preempt if we’re over budget. This works in the educational context (small batch sizes, low contention), but under real load it could starve running requests.
| Feature | vLLM | NanoGPT |
|---|---|---|
| Scheduling priority | Running requests first, then waiting | Admit first, then preempt |
| Token budget enforcement | Explicit token_budget countdown in both phases |
Token budget checked only at admission |
| Chunked prefill | Native - request gets min(remaining_tokens, token_budget) per step |
External - the caller computes the chunk size |
| Multiple prefill requests per step | Yes - multiple waiting requests can be admitted in one step | No - at most 1 prefilling request at a time |
| Fused prefill + decode | Implicit - running and waiting requests share the same token budget | Explicit - assemble_fused_batch() builds a combined batch |
Lazy allocation vs up-front allocation
When a new request arrives, our scheduler allocates all the physical blocks it will ever need, right at admission time:
def _maybe_admit(self, step):
candidate = self.waiting[0]
blocks_needed = (prompt_len + self.block_size - 1) // self.block_size
if self.block_allocator.num_free < blocks_needed:
return
candidate.block_table = self.block_allocator.allocate_n(blocks_needed)
vLLM allocates blocks lazily, per step. A request only gets the blocks it needs for this step’s tokens. A 1,000-token prompt being chunked into 5 steps only holds blocks for the first 200 tokens until the second step runs. This is more memory-efficient - unused blocks stay in the pool for other requests - but it introduces a failure mode we don’t have: mid-generation allocation failure. What happens when step 3 of your chunked prefill can’t get blocks because someone else took them? That’s where preemption comes in.
Preemption: surgical vs threshold-driven
vLLM’s preemption is demand-driven. It only fires when a specific request tries to allocate and fails:
def _preempt_request(self, request):
self.kv_cache_manager.free(request)
request.status = RequestStatus.PREEMPTED
request.num_computed_tokens = 0
request.num_preemptions += 1
self.waiting.prepend_request(request)
After preempting, it retries the allocation immediately - preempt the lowest-priority running request, take its blocks, give them to the request that needed them. Surgical.
Ours is threshold-driven:
def _maybe_preempt(self):
kv_used = sum(len(req.prompt_tokens) + req.num_generated
for req in self.active + self.prefilling)
while self.active and kv_used > self.max_kv_tokens:
victim = max(self.active, key=lambda r: (r.priority, -r.arrival_time))
victim.clear_cache(self.block_allocator)
victim.prefill_cursor = 0
victim.generated_tokens = []
heapq.heappush(self.waiting, (*key, victim.id, victim))
We check a global memory watermark and preempt proactively. This is easier to reason about (one threshold, one check), but it can preempt more than necessary.
| Feature | vLLM | NanoGPT |
|---|---|---|
| Trigger | Memory allocation failure | KV token count exceeds threshold |
| Timing | During scheduling (demand-driven) | After admission (proactive) |
| Victim selection | Lowest priority, latest arrival | Lowest priority, earliest arrival |
| Requeue position | Front of waiting queue (fast re-admission) | Sorted by priority/arrival |
| Preempt-and-retry | Yes - retries allocation immediately | No - separate phases |
Output processing: separate concerns
The final big difference. In vLLM, the scheduler never touches model outputs. Sampling happens in a separate model runner process. The scheduler sends a SchedulerOutput describing what to compute, the model runner executes it and returns token IDs, and then the scheduler processes those IDs in a dedicated 200-line method:
def update_from_output(self, scheduler_output, model_runner_output):
for req_id, num_tokens_scheduled in num_scheduled_tokens.items():
generated_token_ids = sampled_token_ids[req_index]
new_token_ids, stopped = self._update_request_with_output(request, ...)
outputs[request.client_index].append(EngineCoreOutput(...))
In NanoGPT, we do scheduling, forward passes, sampling, and output processing all in the same loop:
logits_decode = logits[:len(decode_reqs), -1, :]
probs = F.softmax(logits_decode, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
for i, req in enumerate(decode_reqs):
req.generated_tokens.append(idx_next[i].item())
if req.is_done:
scheduler.complete(req)
vLLM’s separation enables async scheduling - the scheduler can plan step N+1 while the GPU is still executing step N. That’s a significant latency win in production. Our tight loop means the scheduler is idle during forward passes and the GPU is idle during scheduling.
What NanoGPT captures vs what production requires
| Concept | NanoGPT | vLLM | Notes |
|---|---|---|---|
| Block table (logical → physical) | ✅ | ✅ | Identical concept |
| Pre-allocated GPU memory pool | ✅ | ✅ | Same tensor layout |
| Block allocator / free list | ✅ (Python list) | ✅ (doubly-linked list) | vLLM: O(1) removal |
| Chained block hashing | ✅ (MD5) | ✅ (configurable) | Same algorithm |
| Prefix cache lookup | ✅ | ✅ | vLLM pre-computes hashes |
| LRU eviction | ✅ (O(n) scan) | ✅ (O(1) from queue front) | Same policy, different perf |
| Reference counting | ❌ | ✅ | Critical for shared blocks |
| Block sharing across requests | ❌ (copies KV data) | ✅ (shared via ref_cnt) | vLLM’s memory advantage |
| O(1) mid-list removal | ❌ | ✅ | Needed for touch() on cache hit |
| Multi-group KV cache | ❌ | ✅ | For hybrid attention (SWA, MLA) |
| LoRA / multimodal hash keys | ❌ | ✅ | Production requirement |
| GPU kernel integration | ❌ (Python indexing) | ✅ (CUDA kernels) | Performance-critical |
| Unified prefill/decode scheduling | ❌ (explicit phases) | ✅ (num_computed_tokens model) |
Enables chunked prefill naturally |
| Running-first scheduling | ❌ (admit first) | ✅ (running first, then waiting) | Prevents starvation |
| Demand-driven preemption | ❌ (threshold-based) | ✅ (allocation failure triggers) | More efficient |
| Lazy block allocation | ❌ (all blocks up-front) | ✅ (per-step allocation) | Better memory utilization |
| Async scheduling | ❌ | ✅ (overlaps with model execution) | Production latency |
| Scheduler/sampler separation | ❌ (inline) | ✅ (separate processes) | Enables async + pipeline parallelism |
What I took away from this
The three biggest differences all trace back to the same root cause: ownership.
1. Block sharing via reference counting. vLLM lets two requests point to the same physical block. NanoGPT copies. The difference is ref_cnt - a single integer field on the block object that changes everything downstream: shared blocks need safe eviction, safe eviction needs reference tracking, reference tracking needs O(1) free-list manipulation, and O(1) free-list manipulation needs an intrusive linked list. One field, four consequences.
2. Metadata separated from data. Because vLLM’s KVCacheBlock doesn’t hold KV tensors, it’s tiny and cheap to create, copy, and reason about. Sharing a block means sharing a pointer. In NanoGPT, the block IS the data, so sharing a block means sharing tensors, which means managing concurrent access, which is exactly the complexity we were trying to avoid.
3. Eager hashing. vLLM computes block hashes once, when tokens arrive, and stores them on the request. NanoGPT recomputes from scratch on every lookup. Same algorithm, but the caching of intermediate results makes the production version faster for long prompts.
The pattern here is consistent. NanoGPT makes the simple, obvious choice at each decision point, and those choices compose into a system that works but doesn’t scale. vLLM makes the non-obvious choice - intrusive linked lists, separated metadata, eager hashing, lazy allocation - and those choices compose into a system that handles 100K+ blocks and thousands of concurrent requests.
Neither is “better” in the abstract. If you’re trying to learn how LLM serving works, NanoGPT’s code is far easier to read. If you’re trying to serve Llama 405B to a million users, you need vLLM’s design. The value of building the simple version first is that it gives you the vocabulary to understand why the complex version exists.
CZ