NanoGPT: Guided Decoding
Guided Decoding: Teaching a Language Model to Color Inside the Lines
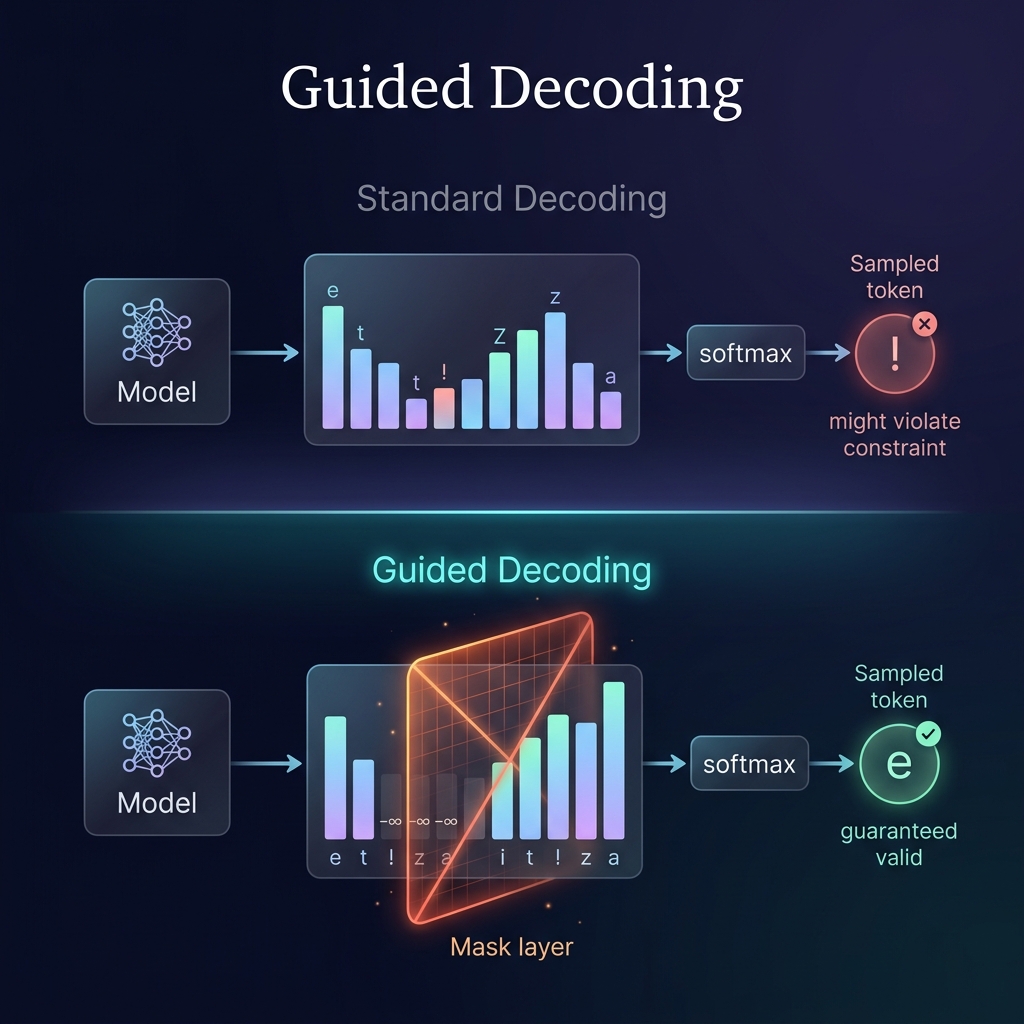
Every generate function we’ve built so far has the same structure: get logits, softmax, sample. The model picks whatever token it wants.
But what if you need the output to follow a format? A character name in uppercase, then a colon, then dialogue in lowercase, then a newline - Shakespeare’s own convention. With unconstrained generation, you’d generate text and hope it happens to look right. If it doesn’t, you throw it away and try again. That’s wasteful, unreliable, and fundamentally the wrong approach.
Guided decoding solves this by adding a single step between getting logits and calling softmax: mask out every token that would violate the constraint. The model can only sample from valid tokens. The output is guaranteed to satisfy the pattern. And the beautiful part: the model’s forward pass, the KV cache, the attention - none of it changes.
Standard decoding:
logits = model(input)
probs = softmax(logits) # all 65 tokens are candidates
token = sample(probs) # might violate your constraint
Guided decoding:
logits = model(input)
logits[disallowed] = -inf # mask out invalid tokens
probs = softmax(logits) # only valid tokens get probability mass
token = sample(probs) # guaranteed to satisfy constraint
This post walks through a from-scratch implementation of guided decoding for NanoGPT, building from the simplest possible version to a finite state machine that compiles patterns into per-step token masks.
Why This Matters
Guided decoding is how production LLM engines enforce structured output. When you tell GPT-4 to respond in JSON, or ask Claude to fill a function signature, the inference engine isn’t hoping the model cooperates. It’s masking the logits so the model can’t produce invalid output.
vLLM uses the outlines library to compile JSON schemas and regular expressions into finite state machines.
SGLang uses xgrammar to do the same with context-free grammars.
Both systems use the same core mechanism: at each decoding step, query the FSM for allowed tokens, mask the logits, and advance the FSM after sampling.
Our implementation does the same thing, but with NanoGPT’s 65-character vocabulary and Shakespeare text. The small vocabulary makes the mechanics completely transparent - you can enumerate every allowed token by hand and verify the FSM is doing the right thing.
The Vocabulary: 65 Characters
NanoGPT’s character-level tokenizer maps the Tiny Shakespeare corpus into 65 tokens:
Token 0: '\n' (newline)
Token 1: ' ' (space)
Token 2: '!'
...
Token 13: 'A'
Token 14: 'B'
...
Token 38: 'Z'
Token 39: 'a'
...
Token 64: 'z'
The first step is organizing these into reusable character classes:
def build_char_classes(stoi):
classes = {}
for char, token_id in stoi.items():
if char.isupper():
classes.setdefault('UPPER', set()).add(token_id)
elif char.islower():
classes.setdefault('LOWER', set()).add(token_id)
elif char.isdigit():
classes.setdefault('DIGIT', set()).add(token_id)
elif char == '\n':
classes.setdefault('NEWLINE', set()).add(token_id)
elif char == ' ':
classes.setdefault('SPACE', set()).add(token_id)
else:
classes.setdefault('PUNCT', set()).add(token_id)
classes['LETTER'] = classes['UPPER'] | classes['LOWER']
classes['ANY'] = set(stoi.values())
return classes
This produces:
DIGIT ( 1 tokens): 3
LETTER (52 tokens): ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
LOWER (26 tokens): abcdefghijklmnopqrstuvwxyz
NEWLINE ( 1 tokens): \n
PUNCT (11 tokens): !$&',-.:;?
SPACE ( 1 tokens): (space)
UPPER (26 tokens): ABCDEFGHIJKLMNOPQRSTUVWXYZ
ANY (65 tokens): (everything)
Note the subtlety: '\n' and ' ' are checked explicitly before falling through to PUNCT.
The original implementation used char.isspace(), which caught both '\n' and ' ' in the same bucket.
That’s a problem because newline and space have very different semantic roles in Shakespeare’s format - newline terminates a line, space separates words.
They need to be in separate classes so FSM transitions can distinguish them.
Level 1: Static Per-Position Masks
The simplest form of guided decoding: define a fixed mask for each generation step before generation starts. The mask doesn’t depend on what was generated - it’s predetermined.
def apply_token_mask(logits, allowed_token_ids):
if len(allowed_token_ids) == 0:
raise ValueError("allowed_token_ids cannot be empty")
mask = torch.zeros(vocab_size, dtype=bool, device=logits.device)
mask[list(allowed_token_ids)] = True
logits = logits.masked_fill(~mask, float('-inf'))
return logits
The masking primitive creates a boolean tensor of size vocab_size (65), sets True for allowed tokens, then uses masked_fill to set everything else to -inf.
After softmax, -inf becomes 0 probability.
The remaining tokens get their probability mass redistributed proportionally.
This is the key insight about guided decoding: the model still influences which allowed token is most likely.
You’re constraining the output space, not overriding the model’s preferences within that space.
If only lowercase letters are allowed and the model thinks 'e' is 3x more likely than 't', that preference is preserved.
The static generate loop is nearly identical to KV-cached generation:
def generate_guided_static(model, idx, masks):
model.eval()
clear_kv_cache(model)
logits, _ = model(idx)
for i in range(len(masks)):
logits = logits[:, -1, :]
logits = apply_token_mask(logits, masks[i]) # ← the only new line
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
logits, _ = model(idx, start_pos=idx.shape[1] - 1)
model.train()
return idx
One line added. The KV cache prefill, the decode loop, the position embedding offset - all unchanged. This is what “orthogonal to existing optimizations” looks like in practice.
Test: 5 Lowercase Letters + Newline
masks = [lowercase_ids] * 5 + [newline_ids]
output = generate_guided_static(m, prompt, masks)
── Static mask test (5 lowercase + newline) ──
Generated: '\x00xhsht\n'
✓ Constraint satisfied!
The \x00 is the null prompt token (token ID 0, character \n).
The generated suffix is xhsht\n - five lowercase letters followed by a newline, exactly as specified.
The model chose x, h, s, h, t from its learned Shakespeare distribution, but it could only choose lowercase.
The assertion confirms: every character is lowercase, and the last character is a newline.
This is a 100% constraint satisfaction rate. Not “usually” satisfies the constraint. Not “tends to follow the pattern.” Guaranteed, by construction, every time.
Level 2: Finite State Machine
Static masks fall apart when the constraint depends on what was generated. “One or more uppercase letters” doesn’t have a fixed length - the model decides how many uppercase letters to produce before transitioning to the next part of the pattern. You can’t precompute a mask list because you don’t know how long each segment will be.
The solution is a finite state machine. Each state represents a position in the pattern. Each transition is labeled with a set of tokens that advance to the next state. At each generation step, the FSM reports which tokens are allowed (the union of all transitions from the current state), and after sampling, it advances to the appropriate next state.
class GuidedFSM:
def __init__(self):
self.transitions = {} # state_id -> list of (token_set, next_state_id)
self.accept_states = set()
self.current_state = 0
def add_transition(self, from_state, token_set, to_state):
if from_state not in self.transitions:
self.transitions[from_state] = []
self.transitions[from_state].append((token_set, to_state))
def allowed_tokens(self):
allowed = set()
if self.current_state not in self.transitions:
return allowed
for ts, nt in self.transitions[self.current_state]:
allowed.update(ts)
return allowed
def advance(self, token_id):
for ts, nt in self.transitions[self.current_state]:
if token_id in ts:
self.current_state = nt
return True
return False
def is_complete(self):
return self.current_state in self.accept_states
The FSM is small - four methods, no dependencies.
allowed_tokens() returns a set, which is exactly what apply_token_mask needs.
advance() finds the matching transition and updates the state.
is_complete() checks if we’ve reached an accept state, which tells the generate loop to stop.
Building the Shakespeare Format FSM
The pattern UPPER+: LOWER+\n (a character name, colon, space, dialogue, newline) compiles into this state machine:
State 0 ──[A-Z]──→ State 1 (must see at least 1 uppercase)
State 1 ──[A-Z]──→ State 1 (self-loop: more uppercase ok)
State 1 ──[:]────→ State 2 (colon ends the name)
State 2 ──[ ]────→ State 3 (space after colon)
State 3 ──[a-z]──→ State 4 (must see at least 1 lowercase)
State 4 ──[a-z]──→ State 4 (self-loop: more lowercase ok)
State 4 ──[\n]───→ State 5 (newline terminates) → ACCEPT

Built manually:
fsm = GuidedFSM()
fsm.add_transition(0, char_classes['UPPER'], 1) # must see >= 1 uppercase
fsm.add_transition(1, char_classes['UPPER'], 1) # self-loop: more uppercase
fsm.add_transition(1, {stoi[':']}, 2) # colon
fsm.add_transition(2, {stoi[' ']}, 3) # space
fsm.add_transition(3, char_classes['LOWER'], 4) # must see >= 1 lowercase
fsm.add_transition(4, char_classes['LOWER'], 4) # self-loop: more lowercase
fsm.add_transition(4, {stoi['\n']}, 5) # newline
fsm.accept_states = {5}
Notice the two-state pattern for + (one or more): State 0 must transition to State 1 on an uppercase letter (guaranteeing at least one match), and State 1 self-loops (allowing more).
This is exactly how regular expression engines handle the + quantifier internally.
The Guided Generate Loop
def generate_guided(model, idx, fsm, max_new_tokens):
model.eval()
clear_kv_cache(model)
fsm.reset()
logits, _ = model(idx)
for _ in range(max_new_tokens):
logits = logits[:, -1, :]
allowed = fsm.allowed_tokens() # ← query FSM
logits = apply_token_mask(logits, allowed) # ← mask logits
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
fsm.advance(idx_next.item()) # ← advance FSM
if fsm.is_complete(): # ← stop at accept
break
logits, _ = model(idx, start_pos=idx.shape[1] - 1)
model.train()
return idx
The FSM runs entirely on the CPU, as a pure Python set lookup - no tensors, no gradients, no GPU involvement.
Test Results: Shakespeare Format
Running the FSM-guided generation 5 times with different seeds:
── FSM test (UPPER+: LOWER+\n) ──
Generated: '\x00WHIS: thing\n'
Run 0: 'WHIS: thing\n'
Run 1: 'ING: t\n'
Run 2: 'TH: therser\n'
Run 3: 'HE: the\n'
Run 4: 'THER: s\n'
Every single output matches the pattern [A-Z]+: [a-z]+\n.
Let’s break down what these results demonstrate:
Constraint satisfaction is absolute. Across all 5 runs, every output has uppercase letters, then a colon, then a space, then lowercase letters, then a newline. The FSM makes constraint violation impossible by construction - tokens that would violate the pattern never receive probability mass.
The model still has preferences.
The outputs aren’t random character salad.
WHIS, ING, TH, HE, THER - these look like fragments of Shakespeare character names.
The model has learned character-level patterns from the training data, and those preferences survive masking.
HE: the is particularly nice - it looks like a plausible Shakespeare line fragment.
Variable-length segments work correctly.
WHIS is 4 uppercase characters.
ING is 3.
HE is 2.
thing is 5 lowercase characters.
t is 1.
therser is 7.
The FSM’s self-loop states allow the model to choose segment lengths naturally, driven by its learned probability distribution.
The + quantifier enforces at least one.
Every output has at least one uppercase letter and at least one lowercase letter.
The two-state construction (mandatory transition + self-loop) prevents empty segments.
You never see : \n (zero uppercase) or NAME: \n (zero lowercase).
Level 2 Bonus: The Pattern Compiler
Manually constructing FSMs is tedious and error-prone.
The pattern compiler automates it by walking through a list of (class_or_literal, quantifier) tuples and emitting states:
def compile_pattern(pattern_elements, char_classes, stoi):
fsm = GuidedFSM()
state_id = 0
for class_or_char, quantifier in pattern_elements:
# Resolve the token set: either a named character class or a literal char
if class_or_char in char_classes:
token_set = char_classes[class_or_char]
else:
token_set = {stoi[class_or_char]}
if quantifier == '1':
# Exactly one: state_id --{tokens}--> state_id+1
fsm.add_transition(state_id, token_set, state_id + 1)
state_id += 1
elif quantifier == '+':
# One or more:
# state_id --{tokens}--> state_id+1 (must match at least one)
# state_id+1 --{tokens}--> state_id+1 (self-loop: more is okay)
fsm.add_transition(state_id, token_set, state_id + 1)
fsm.add_transition(state_id + 1, token_set, state_id + 1)
state_id += 1
fsm.accept_states = {state_id}
return fsm
The compiler does two things: resolve token sets and emit state transitions.
Resolving token sets: If the element name exists in char_classes (e.g., 'UPPER'), use the class’s token set (26 token IDs).
Otherwise, treat it as a literal character and look up its single token ID in stoi (e.g., ':' maps to {stoi[':']}).
Emitting transitions: For quantifier '1' (exactly one), emit a single transition and advance the state counter.
For quantifier '+' (one or more), emit two transitions: the mandatory first-match and the self-loop.
The state counter advances by 1 in both cases.
The pattern UPPER+: LOWER+\n is expressed as:
pattern = [
('UPPER', '+'), # one or more uppercase letters
(':', '1'), # literal colon
(' ', '1'), # literal space
('LOWER', '+'), # one or more lowercase letters
('\n', '1'), # literal newline
]
fsm = compile_pattern(pattern, char_classes, stoi)
This produces the exact same 6-state FSM as the manual construction. We can verify by inspecting the compiled FSM’s transition table:
State 0 ──[26 tokens]──→ State 1 (UPPER, mandatory first)
State 1 ──[26 tokens]──→ State 1 (UPPER, self-loop)
State 1 ──[{52}]───────→ State 2 (colon)
State 2 ──[{53}]───────→ State 3 (space)
State 3 ──[26 tokens]──→ State 4 (LOWER, mandatory first)
State 4 ──[26 tokens]──→ State 4 (LOWER, self-loop)
State 4 ──[{54}]───────→ State 5 (newline)
Accept states: {5}
Test: Compiled Pattern
── compile_pattern test ──
Generated: '\x00SES: sthe\n'
Same format as the manual FSM test. The compile_pattern output is indistinguishable from the manually constructed FSM - because it is the same FSM, just built automatically.
The Orthogonality Argument
The most important design property of guided decoding is that it’s orthogonal to every other inference optimization.
The masking step operates on a logits tensor of shape (vocab_size,).
It doesn’t know or care how those logits were produced.
They could come from:
- A full-recompute forward pass (no KV cache)
- A KV-cached decode step (one token at a time)
- A speculative decoding verification pass (K+1 tokens at once)
- A chunked prefill batch
- A paged attention implementation
- A quantized model
All of these produce a logits tensor and feed it into softmax.
Guided decoding inserts one operation between those two steps: logits[disallowed] = -inf.
The generate loop gains 3 lines (allowed_tokens, apply_token_mask, advance), and everything upstream is untouched.
This is why production engines implement guided decoding as a separate module.
vLLM’s outlines integration and SGLang’s xgrammar both follow the same architecture:
| NanoGPT (ours) | vLLM | SGLang |
|---|---|---|
GuidedFSM |
outlines FSM from regex/JSON schema |
xgrammar CFG-based FSM |
allowed_tokens() |
Guide.get_next_instruction() |
GrammarMatcher.get_next_token_bitmask() |
apply_token_mask() |
_apply_logits_processors() |
apply_token_bitmask_inplace() |
advance(token) |
Guide.advance(token) |
GrammarMatcher.accept_token() |
The API surface is identical: compile a specification into an FSM, query it for allowed tokens, mask logits, advance on sample. Production systems add complexity (JSON schema support, CFG grammars, bitmask optimizations for 128K-token vocabularies, batch-level mask caching), but the core loop is exactly what we built in ~200 lines.
What Guided Decoding Can’t Do
It’s worth being explicit about the limitations.
Guided decoding doesn’t make the model try to follow the pattern.
A common misconception: the model doesn’t know about the constraint.
Its forward pass produces the same logits whether masking happens or not.
If the model’s preferred next token is ! but the FSM only allows [a-z], the model doesn’t “adjust” - we just remove ! from the candidates and redistribute probability.
The model might be confused by the resulting sequence (it never wanted to go this way), which can degrade output quality.
Tighter constraints degrade output quality.
When only 1 out of 65 tokens is allowed, the model’s preferences are irrelevant - the FSM is doing all the work.
When 26 out of 65 tokens are allowed (e.g., LOWER), the model still has meaningful influence over which lowercase letter to pick.
This is a fundamental tradeoff: constraint strictness vs. output naturalness.
Regular expressions can’t express all useful constraints.
Our FSM handles patterns expressible as regular languages.
But constraints like “generate valid JSON with balanced braces” or “generate a syntactically correct Python function” require context-free grammars (or beyond).
This is why SGLang uses xgrammar (a CFG engine) rather than a pure regex-to-FSM approach.
Extending our system to CFGs would require a pushdown automaton - a significantly more complex data structure.
The Code Structure
The full implementation (nanogpt-guided-decoding.py) adds 6 new components to the existing KV-cached NanoGPT:
| Component | Lines | What it does |
|---|---|---|
build_char_classes() |
~15 | Maps 65-char vocab into reusable character classes |
apply_token_mask() |
~5 | Masks a logits tensor so only allowed tokens survive softmax |
generate_guided_static() |
~12 | Level 1: static per-position masks |
GuidedFSM class |
~40 | Level 2: state machine with transitions, allowed_tokens, advance |
generate_guided() |
~15 | Level 2: FSM-guided generation loop |
compile_pattern() |
~20 | Level 2 bonus: builds a GuidedFSM from pattern tuples |
Total new code: ~107 lines.
The model architecture, KV cache, training loop, and embedding tables are completely unchanged from nanogpt-kv-cache.py.
Summary
Guided decoding inserts a single masking step into the generate loop to guarantee output conforms to a pattern. The implementation has three levels of increasing sophistication:
-
Static masks establish the core mechanism: create a boolean mask, apply it to logits before softmax.
-
Finite state machines handle variable-length patterns by tracking position in a state diagram. The FSM reports allowed tokens at each step and advances on sample.
-
Pattern compilation automates FSM construction from a declarative specification. Walk through pattern elements, emit states and transitions.
The system achieves 100% constraint satisfaction across all tests and the model’s learned preferences are preserved within the allowed token space.
The entire implementation is orthogonal to the model architecture, KV cache, and every other inference optimization in the NanoGPT stack.
You can find the code in nanogpt-guided-decoding.py in my nanoGPT inference repository, here.
CZ