NanoGPT: Tree-Based Speculative Decoding
Tree-Based Speculative Decoding
Ok so we previously built speculative decoding for NanoGPT. The idea was nice: a cheap bigram draft model proposes K tokens, the expensive target model verifies all K in a single forward pass, and we accept or reject each one with rejection sampling. When the draft model is decent, we get multiple tokens per forward pass. When it’s bad, we fall back to the target’s distribution and lose nothing statistically.
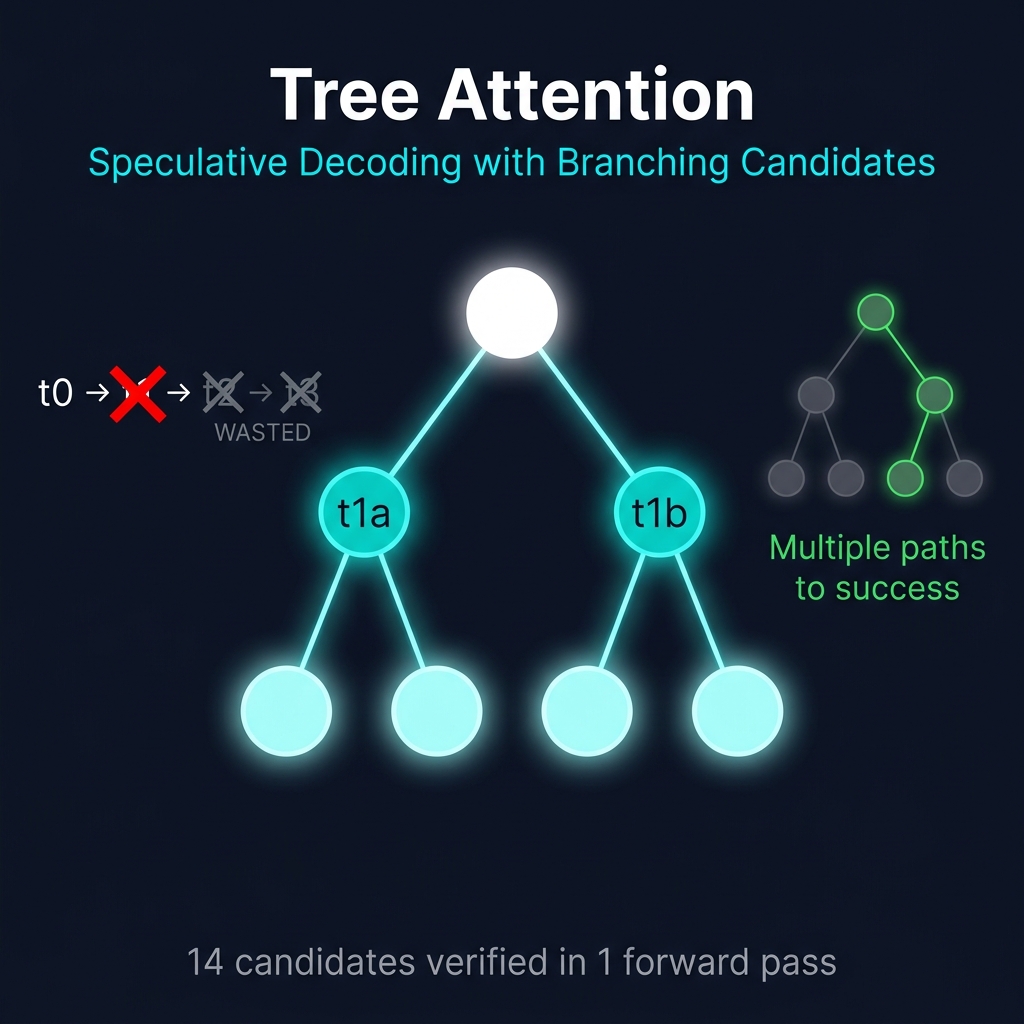
But there’s something deeply wasteful about the chain approach. Look at what happens when the draft proposes 4 tokens and the second one gets rejected:
Draft chain: t0 → t1 → t2 → t3
✗ rejected
(t2, t3 are wasted — we can't use them)
We spent compute generating t2 and t3, and the target model spent compute verifying them, but the moment t1 is rejected those tokens are useless. They were conditioned on t1 being correct, and it wasn’t.
What if we could hedge our bets?
Draft tree: t0 → t1a → t2a
→ t2b
→ t1b → t2c
→ t2d
Now if t1a is rejected, t1b might still be accepted. And if t1a IS accepted but t2a is rejected, t2b is waiting right there. Six candidates verified in one forward pass instead of four, with more paths to success.
This is tree-based speculative decoding. The insight that makes it work is almost embarrassingly simple: the transformer’s attention mechanism already supports arbitrary causal dependency patterns. A standard causal mask encodes a linear chain. A tree attention mask encodes a tree. The math is identical.
The Tree
Let’s start with the data structure. Each node in the speculation tree holds a token ID, the draft model’s probability distribution at that node (we need this for rejection sampling later), a pointer to its parent, a list of children, and its depth in the tree:
@dataclass
class TreeNode:
token_id: int
draft_probs: Optional[torch.Tensor] # (vocab_size,) — None for root
parent: Optional['TreeNode']
children: List['TreeNode']
depth: int # 0 = root (current_token)
linear_idx: int = -1 # index in DFS-flattened list
accepted: bool = False # filled by accept_reject_tree()
resampled_token: Optional[int] = None # filled on rejection
The root is the current token - the last token we actually committed. Its children are the first-level draft candidates. Each of those has its own children, and so on to depth D.
Building the tree is a straightforward recursive expansion. At each node, we ask the draft model for its distribution, take the top-W most likely tokens, create a child for each, and recurse:
def draft_tree(draft_model, current_token, depth=3, width=2):
root = TreeNode(token_id=current_token, draft_probs=None,
parent=None, children=[], depth=0)
def expand(node, remaining_depth):
if remaining_depth == 0:
return
probs = draft_model.get_probs(node.token_id)
next_token_ids = torch.topk(probs, width).indices
for token_id in next_token_ids:
child = TreeNode(
token_id=token_id.item(),
draft_probs=probs,
parent=node,
children=[],
depth=node.depth + 1,
)
node.children.append(child)
expand(child, remaining_depth - 1)
expand(root, depth)
return root
Why topk instead of sampling?
Because with a bigram draft model and a 65-character vocabulary, the top-2 tokens already cover most of the probability mass.
Sampling would waste tree budget on tokens with 0.01 probability that will almost certainly be rejected.
A depth-3, width-2 tree has 2 + 4 + 8 = 14 candidate nodes. That’s 14 candidates verified in one forward pass - compare that with chain speculative decoding’s 4.
The Hard Part: Flattening the Tree
The transformer expects a flat (1, T) tensor, not a tree.
So we need to serialize the tree into a sequence and build a custom attention mask that preserves the tree’s dependency structure.
DFS order is the natural choice because it keeps ancestors contiguous:
def flatten_tree(root):
nodes = []
def dfs(node):
for child in node.children:
child.linear_idx = len(nodes)
nodes.append(child)
dfs(child)
dfs(root)
N = len(nodes)
tokens = [n.token_id for n in nodes]
positions = [n.depth for n in nodes]
# Build the tree attention mask
mask = torch.zeros(N, N, dtype=torch.bool)
for i, node in enumerate(nodes):
mask[i, i] = True # self-attention
for anc in node.ancestors:
if anc.linear_idx >= 0: # skip root (handled via past KV)
mask[i, anc.linear_idx] = True
return nodes, tokens, positions, mask
Let me walk through what this mask looks like concretely. Take our example tree:
cur → c0 → c2
→ c3
→ c1 → c4
→ c5
DFS linearization gives us [c0, c2, c3, c1, c4, c5].
The mask becomes:
c0 c2 c3 c1 c4 c5
c0 [ 1 0 0 0 0 0 ]
c2 [ 1 1 0 0 0 0 ] ← c2 attends to c0 (ancestor)
c3 [ 1 0 1 0 0 0 ] ← c3 attends to c0 (NOT c2 — sibling)
c1 [ 0 0 0 1 0 0 ] ← c1 does NOT attend to c0 (sibling!)
c4 [ 0 0 0 1 1 0 ] ← c4 attends to c1
c5 [ 0 0 0 1 0 1 ] ← c5 attends to c1 (NOT c4)
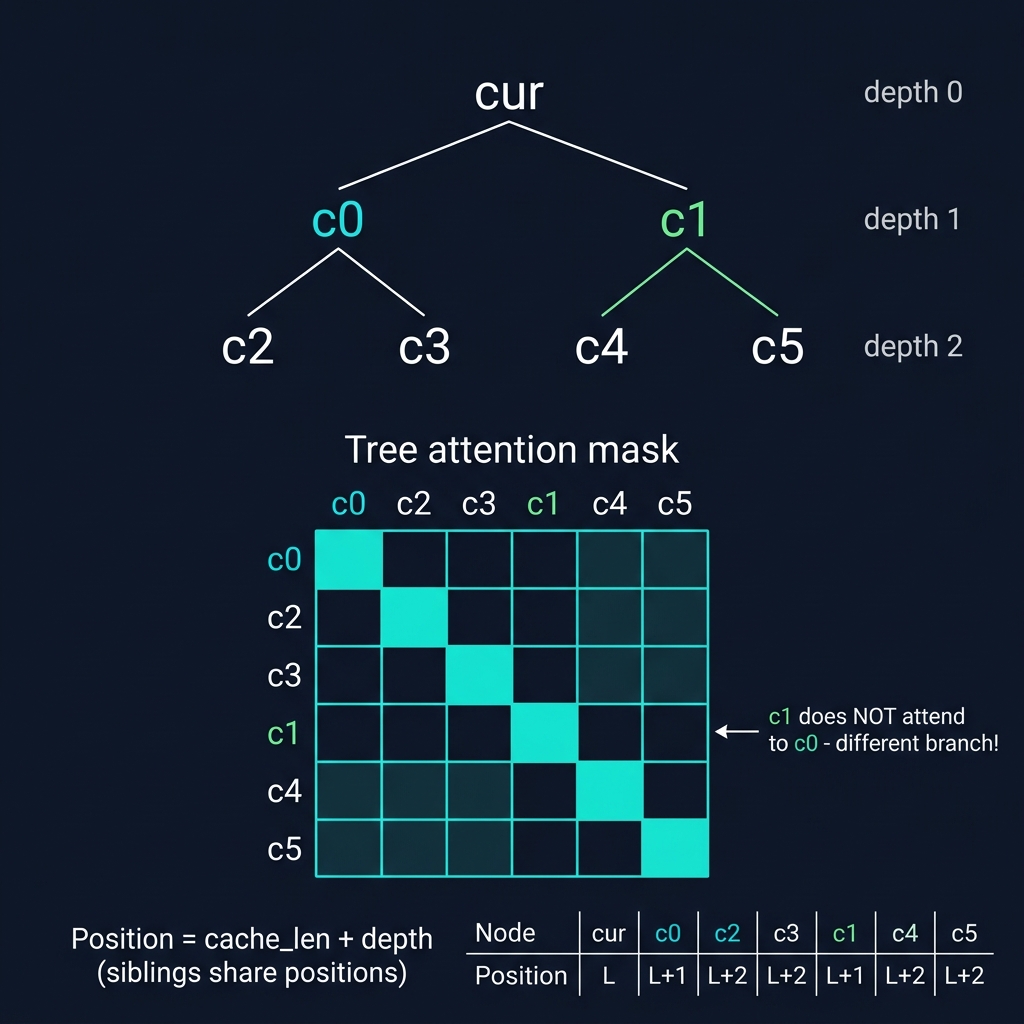
Look carefully at row c1. In a standard causal mask, c1 would attend to everything before it - c0, c2, c3. But c0, c2, c3 are on a different branch. c1 is a sibling of c0, not a descendant. If we let c1 attend to c0, the model would condition c1’s representation on c0 being the chosen token at depth 1 - but c1 IS a different choice at depth 1. That would corrupt the output.
Each token attends only to its ancestors in the tree. That’s the whole trick. The transformer math doesn’t change at all - we just change which entries are masked.
Position indices
There’s one more subtlety. What position index should each node get?
It can’t be the DFS index.
c1 is at DFS index 3, but c1 represents the second option at depth 1 - it’s a candidate for position cache_len + 1, not position cache_len + 3.
If we used DFS indices, the positional embedding for c1 would tell the model “this token is 3 steps past the cache” when it’s actually 1 step past.
The correct position is cache_len + depth_in_tree.
Siblings share the same position because they represent alternative tokens at the same sequence position:
Node: cur c0 c2 c3 c1 c4 c5
Depth: 0 1 2 2 1 2 2
Pos: L L+1 L+2 L+2 L+1 L+2 L+2
Verification: One Forward Pass
Once the tree is flattened and the mask is built, verification is a single forward pass through the target model.
We prepend the root to the token list, build a full (N+1, N+1) mask that includes the root’s self-attention and all nodes’ attention to the root, and call the model:
def verify_tree(target_model, root, past_kvs, cache_len):
nodes, tokens, positions, tree_mask = flatten_tree(root)
all_tokens = [root.token_id] + tokens
all_positions = [p + cache_len for p in [0] + positions]
input_ids = torch.tensor([all_tokens], dtype=torch.long, device=device)
pos = torch.tensor([all_positions], device=device)
N = len(nodes)
full_mask = torch.zeros(N + 1, N + 1, dtype=torch.bool)
full_mask[0, 0] = True # root attends to itself
full_mask[1:, 0] = True # all nodes attend to root
full_mask[1:, 1:] = tree_mask # tree structure for the rest
logits, _, new_kvs = target_model(
input_ids, pos=pos, past_kvs=past_kvs,
tree_attn_mask=full_mask.unsqueeze(0)
)
target_probs = {}
target_probs[root] = F.softmax(logits[0, 0, :], dim=-1)
for i, node in enumerate(nodes):
target_probs[node] = F.softmax(logits[0, i + 1, :], dim=-1)
return target_probs, new_kvs, nodes
After this call, target_probs[node] gives us what the target model thinks should come after node, conditioned only on node’s ancestors.
This is exactly what we need for rejection sampling.
The model change needed for this is minimal.
Head.forward() already takes an attn_mask parameter.
We add one new parameter, tree_attn_mask, that replaces the tril causal mask in the new-token region when provided:
if tree_attn_mask is not None:
causal_mask[:, -T:] = tree_attn_mask[0]
elif T > 1:
causal_mask[:, -T:] = self.tril[:T, :T]
Three lines of code. The entire rest of the model - embeddings, FFN, layernorm, the KV cache concatenation - is unchanged.
Accept/Reject: Walking the Tree
The rejection sampling logic is the same as chain speculative decoding, but now we do it per-node in a tree walk. For each node in DFS order:
for node in nodes:
parent = node.parent
p = target_probs[parent][node.token_id] # target's prob
q = node.draft_probs[node.token_id] # draft's prob
ratio = (p / q).clamp(max=1.0).item()
node.accepted = torch.rand(1).item() < ratio
if not node.accepted:
# Residual distribution for resampling
adjusted = torch.clamp(target_probs[parent] - node.draft_probs, min=0)
adjusted /= adjusted.sum()
node.resampled_token = torch.multinomial(adjusted, num_samples=1).item()
After marking every node, we find the longest accepted root-to-leaf path:
best_path = []
def find_best(node, current_path):
nonlocal best_path
for child in node.children:
if child.accepted:
child_path = current_path + [child.token_id]
if len(child_path) > len(best_path):
best_path = child_path
find_best(child, child_path)
find_best(root, [])
And then append a bonus token - sampled from the target model’s distribution at the deepest accepted node - just like chain speculative decoding:
if best_path:
node = root
for tok in list(best_path):
node = next(c for c in node.children if c.token_id == tok and c.accepted)
bonus = torch.multinomial(target_probs[node], num_samples=1).item()
best_path.append(bonus)
When ALL first-level children are rejected (the draft model was completely wrong), we fall back to the resampled token from the residual distribution. No tokens are wasted - we always get at least one token per iteration, just like chain spec decode.
The Tricky Part: KV Cache Trimming
This is where tree speculative decoding gets genuinely more complex than the chain version.
In chain spec decode, the KV cache after verification looks like:
[past_tokens ... | candidate_0 | candidate_1 | candidate_2 | candidate_3]
If we accept 2 candidates, we just slice: k[:, :cache_len + 3, :].
Contiguous.
Simple.
In tree spec decode, the KV cache after verification looks like:
[past_tokens ... | root | c0 | c2 | c3 | c1 | c4 | c5]
If the accepted path is [c1, c4], we need to keep root, c1, and c4 - indices 0, 3, and 4 in the new-token region.
That’s non-contiguous.
We can’t just slice.
def trim_kv_cache_tree(new_kvs, accepted_path, root, nodes, cache_len):
# Walk the accepted path to find which indices to keep
keep_indices = [0] # root is always kept
node = root
for tok in accepted_path[:-1]: # exclude the bonus token
child = next(c for c in node.children if c.token_id == tok and c.accepted)
keep_indices.append(child.linear_idx + 1) # +1 because root is index 0
node = child
trimmed = []
for layer_kv in new_kvs:
layer_trimmed = []
for (k, v) in layer_kv:
past_k = k[:, :cache_len, :]
new_k = k[:, cache_len:, :]
selected_k = new_k[:, keep_indices, :]
trimmed_k = torch.cat([past_k, selected_k], dim=1)
past_v = v[:, :cache_len, :]
new_v = v[:, cache_len:, :]
selected_v = new_v[:, keep_indices, :]
trimmed_v = torch.cat([past_v, selected_v], dim=1)
layer_trimmed.append((trimmed_k, trimmed_v))
trimmed.append(layer_trimmed)
return trimmed
The keep_indices list is the key insight.
We’re doing an index-gather on the new-token region of the KV cache - keeping exactly those KV entries that correspond to the committed tokens, in the right order.
Everything else (the rejected branches) gets dropped.
The Main Loop
Putting it all together, the generation loop is clean:
@torch.no_grad()
def tree_speculative_generate(target_model, draft_model, prompt_tokens,
max_new_tokens, depth=3, width=2):
generated = []
# 1. Prefill
input_ids = torch.tensor([prompt_tokens], dtype=torch.long, device=device)
positions = torch.arange(len(prompt_tokens), device=device).unsqueeze(0)
logits, _, past_kvs = target_model(input_ids, pos=positions)
probs = F.softmax(logits[0, -1, :], dim=-1)
current_token = torch.multinomial(probs, num_samples=1).item()
generated.append(current_token)
# 2. Tree speculative decode loop
while len(generated) < max_new_tokens:
cache_len = past_kvs[0][0][0].shape[1]
root = draft_tree(draft_model, current_token, depth=depth, width=width)
target_probs, new_kvs, nodes = verify_tree(target_model, root, past_kvs, cache_len)
accepted_path = accept_reject_tree(root, nodes, target_probs)
past_kvs = trim_kv_cache_tree(new_kvs, accepted_path, root, nodes, cache_len)
generated.extend(accepted_path)
current_token = accepted_path[-1]
return generated[:max_new_tokens]
Each iteration: build tree, verify in one pass, accept/reject, trim cache, extend output.
The number of tokens generated per iteration varies - anywhere from 1 (everything rejected, fallback to resampled token) to depth + 1 (entire path accepted + bonus token).
What Actually Happens When You Run It
--- Tree speculative generate (depth=3, width=2) ---
n th'windoher athl th the thel ane than the athe ce thands thore re tL:
qd to?
The tpe the thaPbe tr t the we tour the l the at
The an
is te aner the te thou tur te thandee thy thand s thr anxe t
It’s the same quality of Shakespeare-flavored gibberish as the chain version - which is exactly right. The model is only 57K parameters trained for 120 steps. Tree speculative decoding doesn’t change what the model generates, it changes how efficiently we extract tokens from it.
The acceptance rate with a bigram draft is modest. Bigrams are bad drafters - they can’t capture even basic trigram patterns like “th” followed by “e”. But the tree structure means that when the top draft pick is wrong, the second pick might be right. That’s the whole point.
Why This Matters Beyond NanoGPT
Production inference engines like SpecInfer, Medusa, and Eagle all use tree-based speculation. The details differ - Medusa trains multiple prediction heads instead of using a separate draft model, Eagle uses a learned feature-level drafter - but the core mechanism is the same:
- Build a tree of candidates
- Flatten it with a tree attention mask
- Verify all candidates in one forward pass
- Accept the longest valid path
- Trim the KV cache to match
The tree attention mask is the fundamental primitive.
The code is at nanogpt-tree-attention.py in the nanoGPT inference repository.
CZ