NanoGPT: Disaggregated Prefill and Decode
In the previous post, we added sliding window eviction to cap KV cache memory per request. That post ended with a line about how the scheduler already makes a tradeoff between quality and throughput - evicting KV entries that contribute almost nothing to the attention computation. This post is about a different kind of interference, one that no amount of eviction can fix.
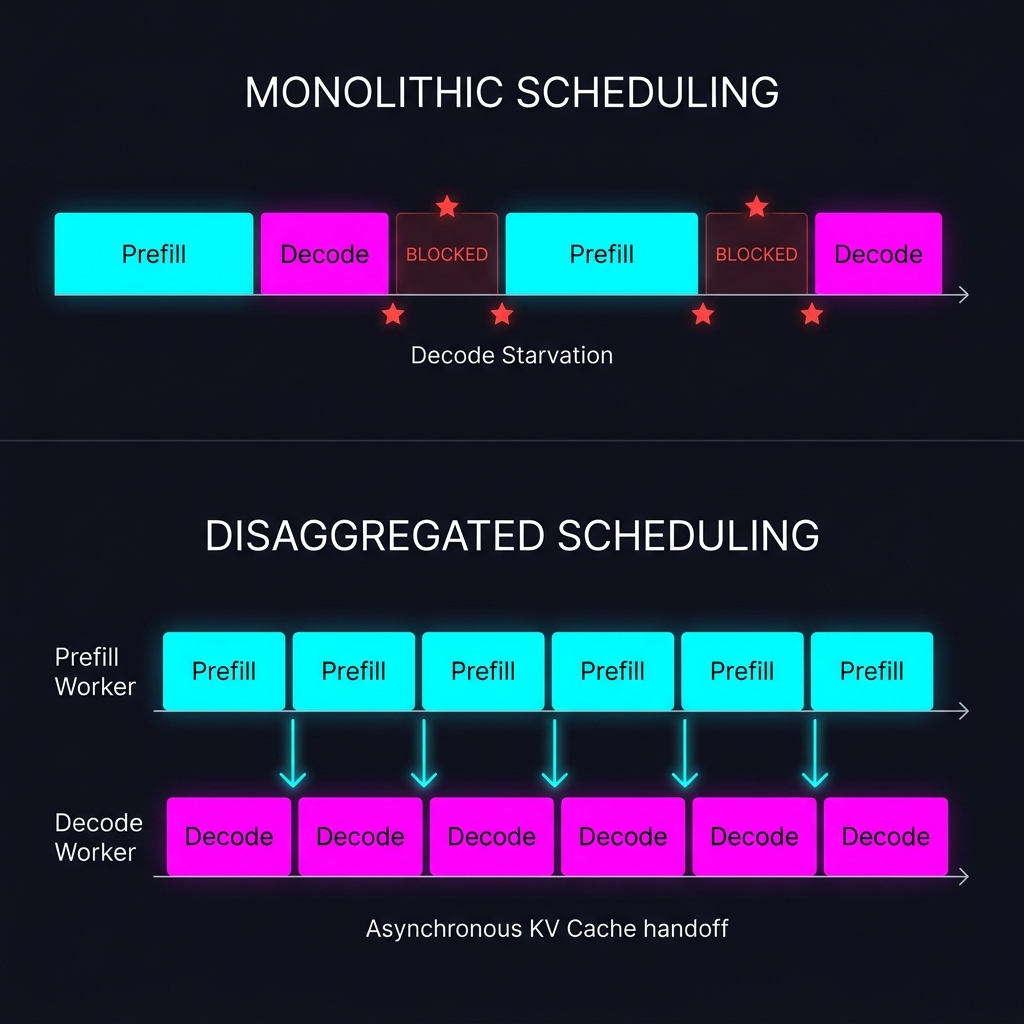
The problem is that prefill and decode want completely different things from the hardware. Prefill ingests the entire prompt in a single dense forward pass - high arithmetic intensity, lots of FLOPs, compute-bound. Decode generates tokens one at a time, fetching the entire KV cache from memory for each new token - memory-bandwidth-bound, very little compute per byte moved. In our monolithic scheduler from the interleaving post, these two phases share the same thread and the same model() call. While prefill is crunching through a long prompt, decode requests sit idle. While decode is streaming one-token-at-a-time, the GPU’s compute units are underutilized.
I’d been reading about how vLLM and DeepSeek handle this in production - they run prefill and decode on separate GPU instances, with a KV cache transfer protocol between them. The idea is called disaggregated prefill, and I wanted to understand it from first principles by building it in NanoGPT.
The constraint: we only have one device. So instead of separate GPUs, I used Python threads and a queue-based KV handoff protocol. The architectural boundary is the same - prefill and decode are independent workers that communicate through a well-defined contract - the physical separation is just smaller.
The three pieces
The design has three components connected by thread-safe queues:
┌─────────────────────────┐
incoming ───────►│ PREFILL WORKER │
requests │ (Thread 1) │
│ • Runs full prefill pass │
│ • Produces KV cache │
│ • Samples first token │
└──────────┬──────────────┘
│
KV cache handoff
(KVTransfer via Queue)
│
┌──────────▼──────────────┐
│ DECODE WORKER │
│ (Thread 2) │
│ • Receives pre-filled KV │
│ • Runs batched decode │
│ • Produces output tokens │
└──────────┬──────────────┘
│
completed requests
│
┌──────────▼──────────────┐
│ COORDINATOR │
│ (Main thread) │
│ • Feeds request_queue │
│ • Collects results │
└───────────────────────────┘
Both workers share the same model object. This sounds dangerous, but it works because PyTorch releases the GIL during tensor operations, the model weights are read-only in eval() mode, and each thread creates its own intermediate tensors. In production, each worker would have its own GPU and model replica - the shared-model approach simulates the same architectural boundary without requiring multiple devices.
The handoff contract
The critical design question is: what exactly does the prefill worker hand to the decode worker? I defined a KVTransfer dataclass as the contract between them:
@dataclass
class KVTransfer:
"""Payload sent from prefill worker to decode worker."""
request_id: int
prompt_tokens: List[int]
max_new_tokens: int
kv_cache: Dict[Tuple[int, int], Tuple[torch.Tensor, torch.Tensor]]
first_token_id: int # the token sampled at the end of prefill
prefill_time_ms: float # for latency tracking
I want to walk through a few design choices here because they weren’t obvious to me at first.
The KV cache is a dictionary keyed by (layer_index, head_index), with each value being a (key_tensor, value_tensor) pair - same representation we’ve been using since the KV cache post. The prefill worker .clone()s these tensors before putting them on the queue. In a real multi-GPU system, this clone would be a network transfer (NCCL, RDMA), but the semantic boundary is the same: the decode worker should not assume it can reach into the prefill worker’s memory.
Including first_token_id in the transfer is a subtle but important detail. The prefill worker doesn’t just compute the KV cache - it also samples the first output token from the last-position logits. This means the decode worker can immediately begin generating from the second token, with the request already carrying one generated token. I initially had the decode worker re-computing logits from the transferred KV cache to get the first token, which was wasteful - the prefill worker already has those logits sitting right there.
The prefill worker
The prefill worker is the simpler of the two - a tight loop that pulls requests from a queue and runs a full forward pass:
def prefill_worker(model, request_queue, kv_transfer_queue, stop_event):
model.eval()
with torch.no_grad():
while not stop_event.is_set():
try:
request = request_queue.get(timeout=0.05)
except queue.Empty:
continue
t0 = time.perf_counter()
prompt = torch.tensor([request.prompt_tokens], device=device)
logits, _, new_kvs = model(prompt)
# Build per-(layer, head) KV cache
kv_cache = {}
for li, bkv in enumerate(new_kvs):
for hi, (k, v) in enumerate(bkv):
kv_cache[(li, hi)] = (k.clone(), v.clone())
# Sample first token
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
first_token = torch.multinomial(probs, num_samples=1)
prefill_ms = (time.perf_counter() - t0) * 1000
transfer = KVTransfer(
request_id=request.id,
prompt_tokens=request.prompt_tokens,
max_new_tokens=request.max_new_tokens,
kv_cache=kv_cache,
first_token_id=first_token.item(),
prefill_time_ms=prefill_ms,
)
kv_transfer_queue.put(transfer)
One key difference from the monolithic scheduler: there’s no chunking. The prefill worker processes the entire prompt in a single forward pass because it doesn’t share a token budget with decode. Remember how in the chunked prefill post we had to split long prompts into chunks to avoid starving decode requests? That constraint is gone. The prefill worker can saturate its compute without throttling to leave room for decode tokens. This is one of the fundamental benefits of disaggregation - you don’t need chunked prefill when prefill has its own execution context.
The timeout=0.05 on queue.get() is a small detail worth mentioning. Without a timeout, the worker blocks indefinitely on an empty queue and the stop_event check never runs. With it, the worker wakes up every 50ms to check if it should shut down. In production you’d use something more sophisticated (condition variables, select-style polling), but for our purposes this is fine.
The decode worker
The decode worker is a continuous batching loop - structurally almost identical to the decode path in our interleaving scheduler, but sourcing pre-filled requests from the transfer queue instead of doing prefill itself:
def decode_worker(model, kv_transfer_queue, results_queue, stop_event,
max_batch_size=4):
model.eval()
active_requests = []
with torch.no_grad():
step = 0
while not stop_event.is_set() or active_requests:
# Drain the transfer queue - admit new pre-filled requests
while not kv_transfer_queue.empty() and len(active_requests) < max_batch_size:
transfer = kv_transfer_queue.get()
req = Request(
id=transfer.request_id,
prompt_tokens=transfer.prompt_tokens,
max_new_tokens=transfer.max_new_tokens,
kv_cache=transfer.kv_cache,
status="active",
)
req.generated_tokens.append(transfer.first_token_id)
req._last_token = torch.tensor(
[[transfer.first_token_id]], device=device
)
req.prefill_cursor = len(req.prompt_tokens)
active_requests.append(req)
if not active_requests:
time.sleep(0.01)
continue
# Standard batched decode
batch_tokens = torch.cat([r._last_token for r in active_requests])
batch_positions = torch.tensor(
[[len(r.tokens_so_far) - 1] for r in active_requests],
device=device,
)
past_kvs, attn_mask, pad_lengths = assemble_batch_cache(active_requests)
logits, _, new_kvs = model(
batch_tokens, pos=batch_positions,
past_kvs=past_kvs, attn_mask=attn_mask,
)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
disassemble_batch_cache(active_requests, new_kvs, pad_lengths)
for i, req in enumerate(active_requests):
req.generated_tokens.append(idx_next[i].item())
req._last_token = idx_next[i:i + 1]
# Retire completed requests
still_active = []
for req in active_requests:
if req.is_done:
results_queue.put(req)
else:
still_active.append(req)
active_requests = still_active
The decode worker never runs a prefill forward pass. It only performs the memory-bandwidth-bound single-token decode, using assemble_batch_cache() and disassemble_batch_cache() - the same left-padded batching functions from the continuous batching post.
There’s a detail in the request reconstruction that took me a minute to get right. When a KVTransfer arrives, the decode worker creates a fresh Request object, but it has to initialize it as if prefill already happened. That means setting prefill_cursor = len(prompt_tokens), appending the first_token_id to generated_tokens, and stashing it in _last_token so the next decode step feeds it to the model. If you forget any of these, the request either re-prefills (wrong) or crashes on the position calculation (also wrong).
The behavioral difference becomes visible in the logs. Where the monolithic scheduler alternates between prefill and decode within a single step:
step 0: prefill req0 (30 tokens), decode batch=0
step 1: prefill req0 (continued), decode batch=0
step 2: decode batch=1 (req0)
step 3: prefill req1, decode batch=1 (req0) ← req0's decode blocked by req1's prefill
The disaggregated version shows the two phases running asynchronously:
[PREFILL] req 0: 30 tokens → KV transfer (2.3ms)
[PREFILL] req 1: 15 tokens → KV transfer (1.1ms)
[DECODE] step 0: batch=1 (req0)
[DECODE] step 1: batch=2 (req0, req1) ← decode never blocked by prefill
[PREFILL] req 2: 20 tokens → KV transfer (1.5ms)
[DECODE] step 2: batch=2 (req0, req1)
[DECODE] step 3: batch=3 (req0, req1, req2)
Prefill doesn’t block decode. Decode doesn’t wait for prefill. The decode batch grows smoothly as pre-filled requests arrive.
The coordinator
The main thread ties everything together - create the workers, feed requests, collect results:
def disaggregated_generate(model, requests, max_batch_size=4):
request_queue = queue.Queue() # main → prefill worker
kv_transfer_queue = queue.Queue() # prefill → decode worker
results_queue = queue.Queue() # decode → main
stop_event = threading.Event()
prefill_thread = threading.Thread(
target=prefill_worker,
args=(model, request_queue, kv_transfer_queue, stop_event),
daemon=True,
)
decode_thread = threading.Thread(
target=decode_worker,
args=(model, kv_transfer_queue, results_queue, stop_event, max_batch_size),
daemon=True,
)
prefill_thread.start()
decode_thread.start()
for req in requests:
request_queue.put(req)
completed = 0
while completed < len(requests):
try:
req = results_queue.get(timeout=0.5)
completed += 1
except queue.Empty:
continue
stop_event.set()
prefill_thread.join()
decode_thread.join()
return requests
The stop_event provides clean shutdown: the prefill worker exits its loop, and the decode worker finishes draining its active requests before terminating. I initially tried just joining the threads without a stop event, and the prefill worker would hang on request_queue.get() forever - it didn’t know there were no more requests coming. The event gives it a way to check “should I stop?” on every iteration.
What the benchmarks show
I built a benchmark suite that runs the same requests through both the monolithic chunked-prefill scheduler and the disaggregated engine, then compares wall time, throughput, TTFT, and average request latency. Six scenarios, each testing a different workload shape.
Smoke test (4 requests, 16-token prompts, 8 new tokens)
| Method | Wall (s) | Gen tok/s | Avg TTFT (ms) | Avg Latency (ms) |
|---|---|---|---|---|
| Monolithic | 0.036 | 894 | 11.32 | 30.34 |
| Disaggregated | 0.060 | 534 | 10.11 | 29.01 |
At this trivially small scale, disaggregation is slower (0.60x throughput). The threading overhead - queue puts/gets, thread synchronization, time.sleep() polls - dominates when there are only 4 requests with 16-token prompts. This is the same lesson as the radix tree benchmarks: caching infrastructure has a fixed cost, and if the workload is too small, that cost exceeds the benefit.
Staggered arrivals (8 requests, 24-token prompts, 10 new tokens)
| Method | Wall (s) | Gen tok/s | Avg TTFT (ms) | Avg Latency (ms) |
|---|---|---|---|---|
| Monolithic | 0.103 | 775 | 49.68 | 81.97 |
| Disaggregated | 0.073 | 1103 | 23.17 | 46.37 |
Here the benefit materializes: 1.42x throughput, 53% lower TTFT, 43% lower latency. With 8 staggered requests, the monolithic scheduler’s head-of-line blocking becomes significant - later requests queue behind earlier prefills. The disaggregated engine processes prefills in parallel with ongoing decodes.
Long prompts (6 requests, 40-token prompts, 8 new tokens)
| Method | Wall (s) | Gen tok/s | Avg TTFT (ms) | Avg Latency (ms) |
|---|---|---|---|---|
| Monolithic | 0.108 | 443 | 64.22 | 96.99 |
| Disaggregated | 0.067 | 716 | 16.61 | 34.38 |
This is the strongest result: 1.62x throughput and a 74% reduction in TTFT. Long prompts amplify the prefill/decode interference because the monolithic scheduler must chunk the 40-token prompt across multiple steps, blocking decode during each prefill chunk. The disaggregated engine processes the full prompt in one shot on the prefill worker while the decode worker continues uninterrupted.
Long decode (6 requests, 16-token prompts, 32 new tokens)
| Method | Wall (s) | Gen tok/s | Avg TTFT (ms) | Avg Latency (ms) |
|---|---|---|---|---|
| Monolithic | 0.187 | 1029 | 60.87 | 144.41 |
| Disaggregated | 0.165 | 1164 | 33.47 | 98.77 |
Moderate gains: 1.13x throughput, 45% lower TTFT. When decode dominates (32 new tokens per request), the decode worker is the bottleneck regardless of architecture. But TTFT still improves because requests enter the decode phase faster.
Stress test (16 requests, 16-token prompts, 10 new tokens)
| Method | Wall (s) | Gen tok/s | Avg TTFT (ms) | Avg Latency (ms) |
|---|---|---|---|---|
| Monolithic | 0.156 | 1025 | 72.62 | 101.51 |
| Disaggregated | 0.150 | 1069 | 52.81 | 77.22 |
At scale: 1.04x throughput, 27% lower TTFT, 24% lower latency. With 16 requests competing for a batch size of 4, both engines are admission-constrained. The disaggregated version still wins on latency because the prefill pipeline never blocks the decode pipeline.
Batch pressure (12 requests, 16-token prompts, batch size 2)
| Method | Wall (s) | Gen tok/s | Avg TTFT (ms) | Avg Latency (ms) |
|---|---|---|---|---|
| Monolithic | 0.133 | 721 | 63.96 | 80.52 |
| Disaggregated | 0.136 | 706 | 53.38 | 68.47 |
Near-parity throughput (0.98x) but still 17% lower TTFT and 15% lower latency. Even under tight batch constraints, disaggregation helps latency.
The pattern across all six scenarios
| Scenario | Throughput Ratio | TTFT Ratio | Latency Ratio |
|---|---|---|---|
| smoke_test | 0.60x | 0.89x | 0.96x |
| staggered_arrivals | 1.42x | 0.47x | 0.57x |
| batch_pressure | 0.98x | 0.83x | 0.85x |
| long_prompts | 1.62x | 0.26x | 0.35x |
| long_decode | 1.13x | 0.55x | 0.68x |
| stress_test | 1.04x | 0.73x | 0.76x |
(Ratios < 1.0 for TTFT/latency = disaggregated is better)
The pattern is clear: disaggregation shines when prefill is expensive relative to decode. The long_prompts scenario - where 40-token prompts would require multiple chunked-prefill steps in the monolithic scheduler - shows a 74% TTFT reduction. The smoke_test scenario - where prompts are tiny and the overhead of threading dominates - shows disaggregation is slightly worse.
This matches the production intuition. vLLM and DeepSeek deploy disaggregated prefill on workloads with long context windows (32K+ tokens), where a single prefill can occupy a GPU for hundreds of milliseconds. On those workloads, the latency-sensitive decode requests absolutely cannot afford to be blocked behind prefill.
A note on token mismatches
The benchmark logs show ⚠ Req N: token mismatch for every request, which looked alarming until I thought about it.
The monolithic and disaggregated engines consume PyTorch’s random number generator in different orders. In the monolithic scheduler, prefill and decode interleave within a single thread, consuming RNG values in a deterministic but interleaved order. In the disaggregated version, the prefill and decode workers are in separate threads - the prefill worker might consume RNG for request 2’s sampling before or after the decode worker consumes RNG for request 0’s next token, depending on thread scheduling.
How this maps to production
| This Implementation | Production (vLLM P/D) |
|---|---|
threading.Thread |
Separate GPU processes |
queue.Queue |
NCCL / RDMA / TCP KV transfer |
Shared model object |
Separate model replicas per GPU |
KVTransfer dataclass |
KV cache transfer protocol (tensor metadata + data) |
clone() KV tensors |
GPU-to-GPU memory copy |
| Single-machine overlap | Multi-node pipeline parallelism |
The architectural pattern is identical - the only difference is what the “boundary” between prefill and decode actually is. In this implementation, it’s a Python queue.Queue. In production, it’s a network link carrying serialized KV tensors between machines. The KVTransfer dataclass maps directly to the wire protocol.
What this educational implementation doesn’t capture is the memory management complexity of production disaggregation: KV cache pooling (like what we compared against SGLang), tensor parallelism across the transfer, page-aligned block transfers, and the scheduling logic for balancing prefill and decode worker utilization. But the fundamental insight - that splitting these two fundamentally different computational phases into independent workers eliminates head-of-line blocking and improves tail latency - comes through clearly even at NanoGPT scale.
What I took away from this
The model doesn’t know anything about disaggregation. model.forward() is called identically whether it’s running prefill or decode - it’s just called from different threads with different inputs. The Head attention implementation, assemble_batch_cache(), disassemble_batch_cache() - none of it changes. All of the disaggregation complexity lives in the threading and queue orchestration above the model.
This is the same pattern we’ve seen across every optimization in this series. Chunked prefill was a scheduling change, and so was continuous batching. The radix tree was a caching change and now disaggregated prefill is a threading change. None of these optimizations touched the model’s forward pass.
Disaggregated prefill is a pure scheduling optimization. It’s recognizing that prefill and decode have different computational profiles and giving them separate execution contexts so they don’t interfere with each other. The elegant part is that you can layer it on top of everything we’ve already built without touching any of the layers below.
You can find the entire sample code here: https://github.com/czhou578/nanoGPT-inference/blob/main/nanogpt-disaggregated-prefill.py
CZ